华为开源 505B 参数 MoE 模型 openPangu-2.0-Pro
华为在 Hugging Face 开源 openPangu-2.0-Pro,该模型为 505B 参数的 MoE 架构,基于昇腾 NPU 训练,激活参数约 18B,支持 512k 上下文。Thinking 版本在 A...
TechFoco

共 22 篇文章,按时间倒序展示。
华为在 Hugging Face 开源 openPangu-2.0-Pro,该模型为 505B 参数的 MoE 架构,基于昇腾 NPU 训练,激活参数约 18B,支持 512k 上下文。Thinking 版本在 A...
月之暗面发布全球首个开源 2.8 万亿参数模型 Kimi K3,基于 Delta Attention 与 Attention Residuals 架构,具备原生视觉能力和 100 万 token 上下文窗口。在 F...

一项针对 Gemma 4 的维吉尼亚密码破解测试显示,该模型在明确指令下可进行长时间深度推理,并在无法解决时选择诚实拒绝而非编造答案,其思维深度具有可调节特性。测试也引发了关于如何更全面评估模型原生推理能力与效率的讨论。

一项实验让Codex自主解决一个真实的机器学习研究问题。AI不仅完成了任务,还独立提出了一个文献中未见的新评估方法,揭示了任务设计、奖励黑客和参考点限制等关键教训。


本文基于 Sebastian Raschka 整理的 40 多个开源大模型架构图谱,分析了 2024 年至 2026 年间 LLM 架构的演进趋势。核心观察是设计语言趋同,但具体技术方案呈现分裂与混搭,反映出行业正...

Lossless Claw 是一个为 OpenClaw 设计的开源插件,它采用有向无环图和智能摘要技术管理对话上下文,旨在突破大语言模型的上下文窗口限制,实现消息的无损存储与高效回溯。

近期发现,用户可通过将付费文章链接提供给谷歌AI,使其通过搜索引擎特权通道获取并总结全文。当访问被阻时,上传空PDF文件再贴链接可欺骗系统成功读取。这一现象降低了绕过付费墙的技术门槛,引发了关于内容付费模式与AI伦...

Anthropic 公开指控 DeepSeek 等中国 AI 公司通过大量 API 调用对 Claude 实施“工业级蒸馏攻击”。然而,Anthropic 自身训练数据来源的版权问题同样受到质疑,事件引发了关于技术...


马斯克公开鼓励用户向 Grok 上传医疗数据以获取第二诊疗意见,此举引发对数据隐私、商业动机及用户信任的广泛讨论。核心争议在于用户主动提交的数据不受 HIPAA 等法规保护,存在被滥用风险。



Google Research 研究发现,在不启用推理模式时,将提示词原样重复一遍可显著提升大语言模型在多项基准测试中的表现,且几乎不增加计算成本。

OpenAI 宣布将在 ChatGPT 免费版和 Go 订阅层级测试广告功能,承诺广告不影响回答内容且与对话分离。此举引发了用户对 AI 中立性、商业模式可持续性及行业未来走向的广泛讨论。


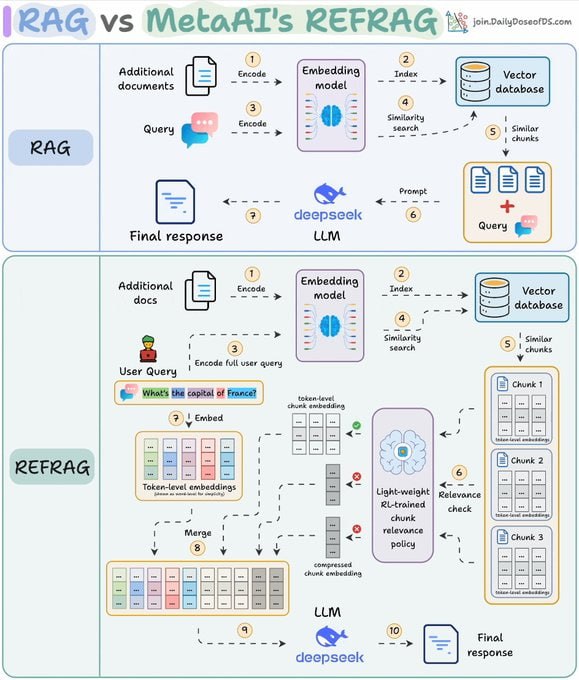
Meta推出的REFRAG技术,通过在嵌入层面对文本块进行压缩,并利用强化学习策略进行相关性筛选,显著减少了送入大语言模型的无关token数量。该方法在提升响应速度、支持更大上下文窗口的同时,保持了模型准确性。
Spider Creator 是一款结合浏览器操作录制与大语言模型的工具,可通过自然语言描述自动生成 Playwright 爬虫脚本,旨在简化重复性数据采集任务的开发流程。

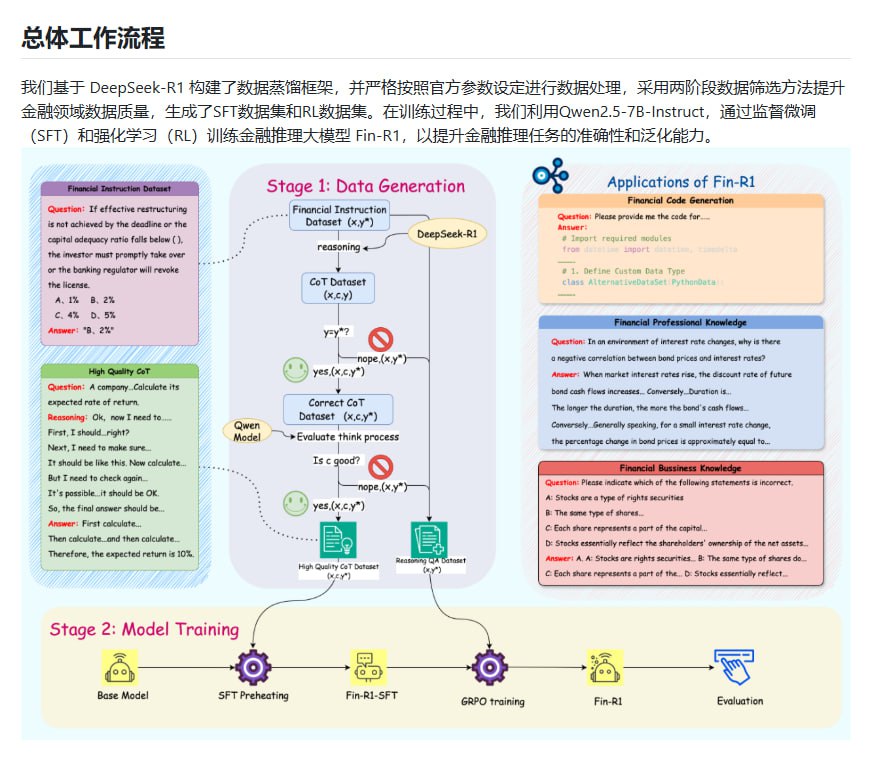
Fin-R1是一款专为金融领域设计的7B参数推理大模型,采用SFT和RL两阶段训练,在FinQA和ConvFinQA等金融推理任务上表现优异,旨在提升模型准确性与泛化能力。
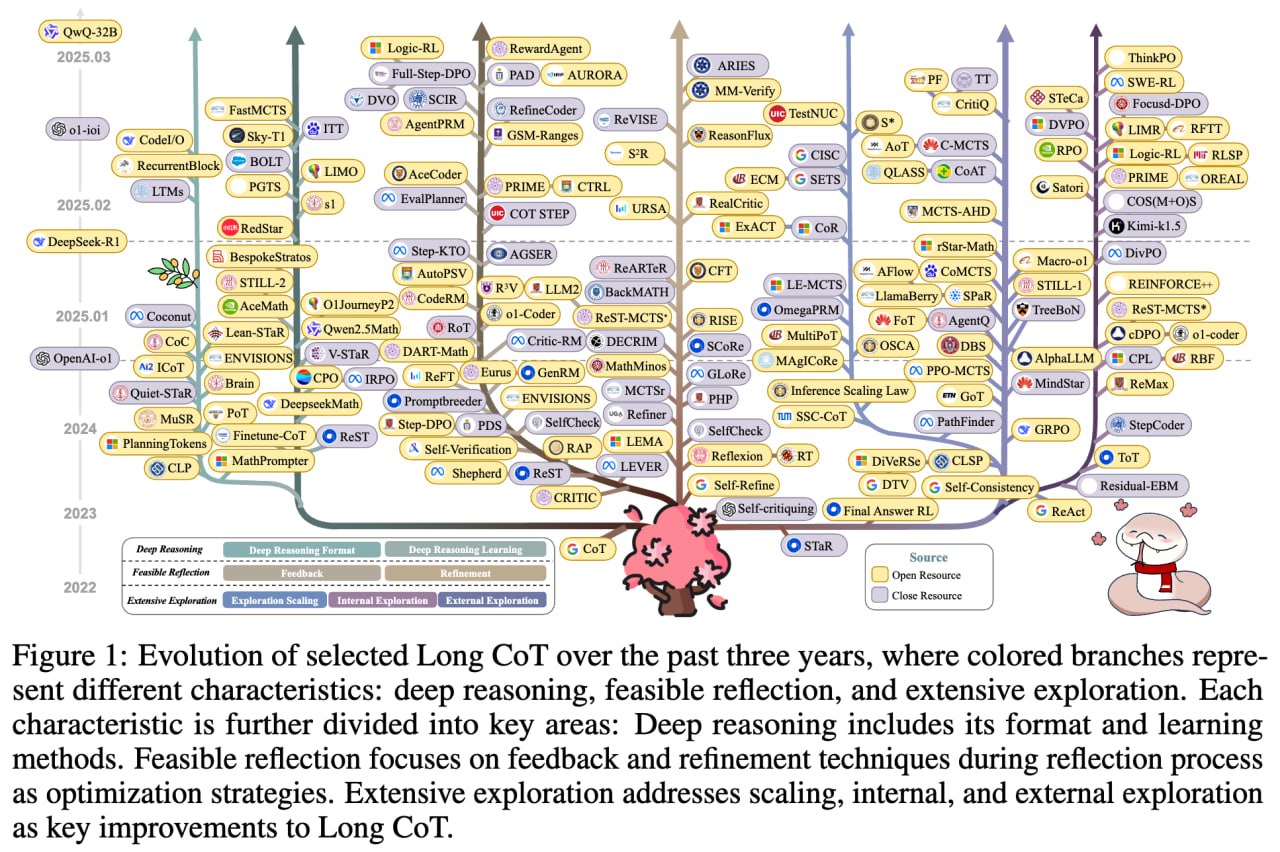
本文介绍了一个专注于提升大语言模型长思维链推理能力的 GitHub 资源库。该库系统性地整理了 600 多篇相关文献,并提炼出深度推理等三大核心特性,旨在填补该领域的研究空白。