百度开源 Unlimited OCR:长文本与多页文档的“一镜...
百度开源 Unlimited OCR,专为长文本与多页文档设计,支持单图/多页解析、两种图像模式、PDF自动切页、多种部署方案,并内置重复抑制机制,适用于学术文献数字化和企业文档处理。
TechFoco

共 17 篇文章,按时间倒序展示。
百度开源 Unlimited OCR,专为长文本与多页文档设计,支持单图/多页解析、两种图像模式、PDF自动切页、多种部署方案,并内置重复抑制机制,适用于学术文献数字化和企业文档处理。
GLM-OCR 将 OCR 全流程整合为单一工具,提供从布局分析到文本识别的完整文档理解方案。在 OmniDocBench V1.5 基准测试中得分 94.62,排名第一。支持复杂表格、公式、代码识别,仅 0.9B...

DeepOCR 是由爱荷华州立大学和普林斯顿大学发起的开源项目,旨在完整复现 DeepSeek-OCR 的训练过程,提供了包括训练和评估在内的全部代码实现。
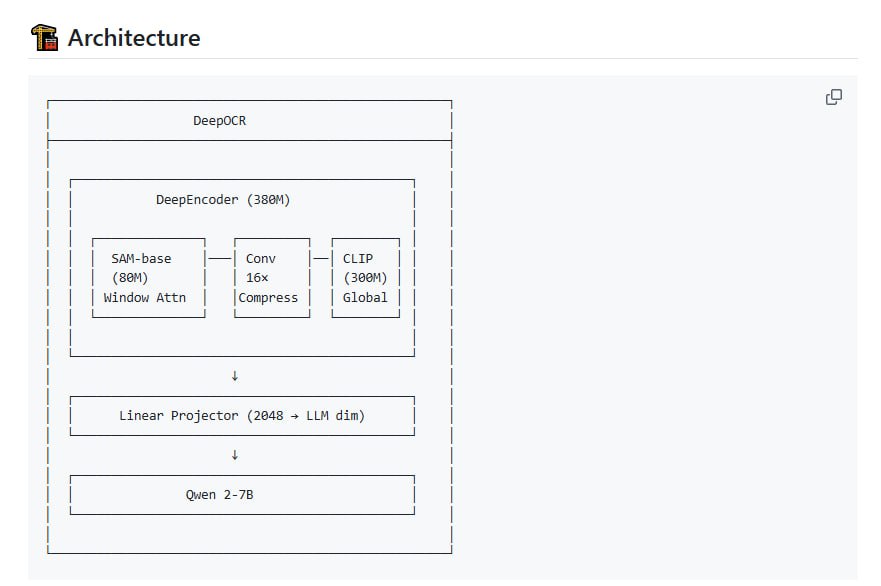
DeepOCR 是由爱荷华州立大学和普林斯顿大学发起的开源项目,旨在提供完整的代码以复现 DeepSeek-OCR 的训练与评估流程,而不仅仅是权重和报告。
olmOCR 2 是一款开源的文档转换工具,专注于将 PDF 及多种格式文档精准转换为纯文本,支持表格、公式等复杂元素。通过结合高质量数据训练与强化学习奖励机制,有效降低了识别中的“幻觉”错误。
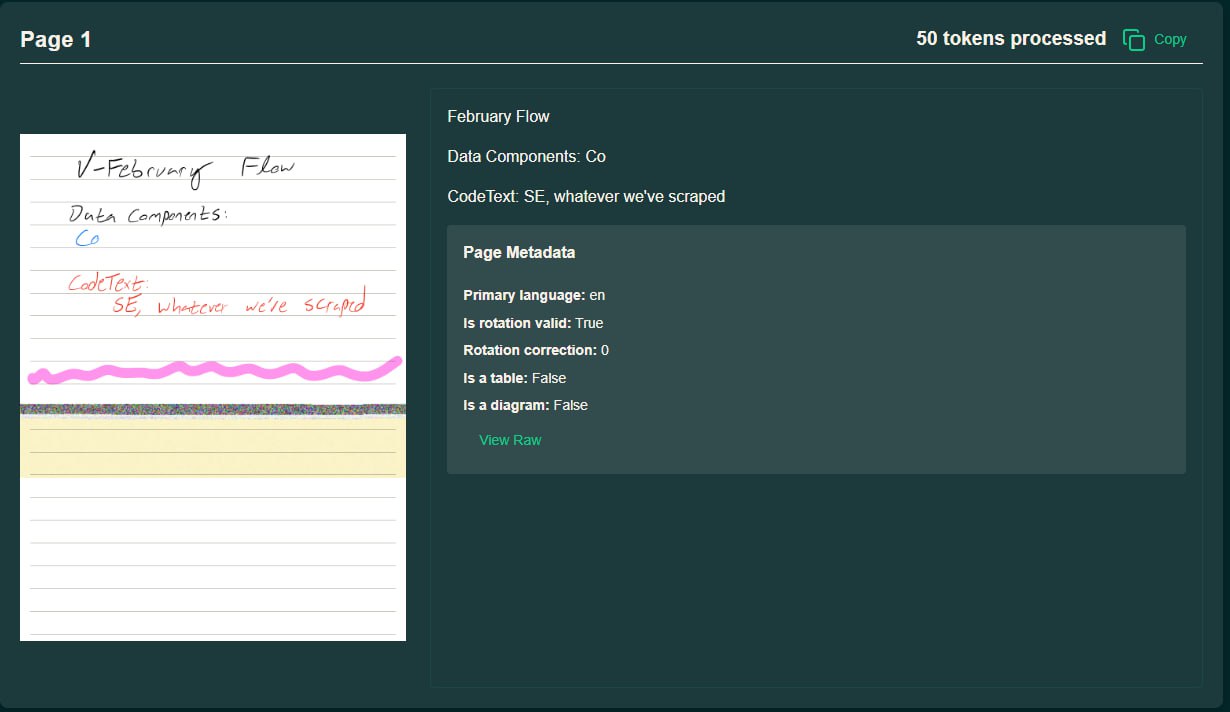
Chandra OCR 是一款开源文档解析工具,支持版面分析、手写体识别,兼容 transformers 和 vLLM,在基准测试中表现优异,但存在部分识别限制。
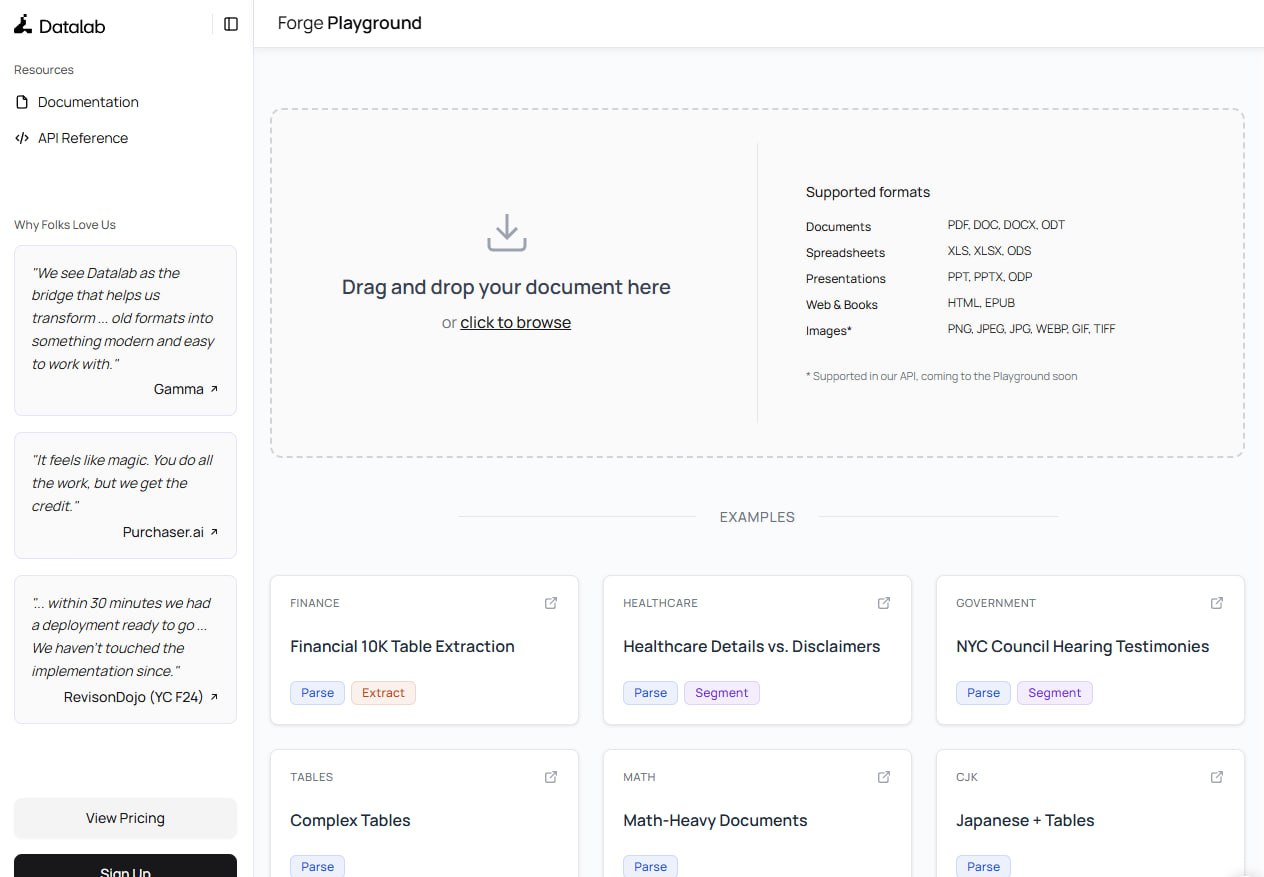
Hugging Face 博客针对开源 OCR 模型选择难题,提供了从模型对比、部署方案到扩展应用的系统性指导,旨在帮助开发者在控制成本与保护隐私的前提下降低使用门槛。

面对 DeepSeek-OCR、PaddleOCR 等众多开源 OCR 模型,如何根据成本、隐私和部署需求进行选择成为关键。Hugging Face 的一篇博客为此提供了系统的挑选、对比与部署指南。
Nanonets-OCR2是一款开源模型,可将图像文档智能转换为结构化的Markdown格式。它不仅能提取文本,还能精准识别LaTeX公式、复杂表格、图表、签名水印等多种元素,并支持多语言、手写文档及视觉问答功能。
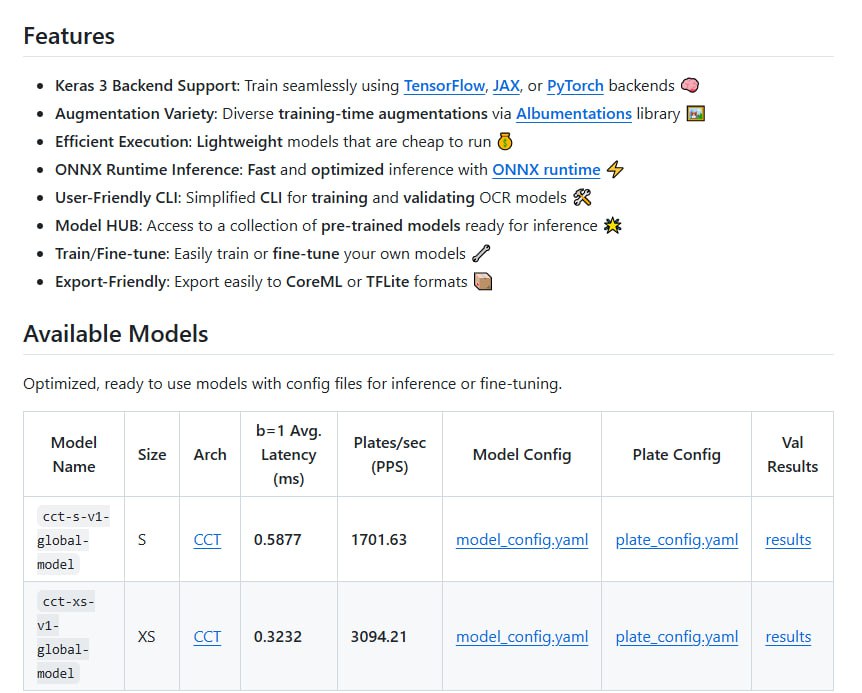
Fast Plate OCR 是一个专为车牌文本识别设计的开源模型,以轻量高效为核心,支持多训练框架与多平台部署,并提供预训练模型与详细教程,便于快速集成与定制。
PHOCR是一款专注于提升多语种文本识别精度的开源工具包,其自研模型PH-OCRv1在文档环境下实现了极低的字符错误率,并支持多种语言与跨平台高效部署。
本文介绍了一款基于机器学习的通用 PDF 文件流 OCR 识别 API,支持多语言混合识别、HTTPS 安全协议、高可用架构,并输出纯文本以利于后续处理。

uniOCR 是一款支持 macOS、Windows 和 Linux 的原生 OCR 工具,通过集成各平台原生 API 与 Tesseract,提供统一接口并利用异步处理提升性能。

docling-api 是一个专注于文档格式转换的后端服务,支持将 PDF、DOCX、PPTX、HTML 及图片等多种格式高效转换为 Markdown。它提供 CPU/GPU 处理模式、同步/异步 API 接口以及...

olmOCR 是一款开源工具,专注于将 PDF 等文档高吞吐量转换为纯文本,同时保持自然阅读顺序。它支持表格、公式和手写体等复杂内容,并采用独特提示技术以提高准确性。

Omni OCR Benchmark 是一个开源基准测试工具,旨在系统评估多模态模型在 OCR 和数据提取任务上的性能。它支持主流模型,并提供 JSON 准确率与文本相似度等关键指标。

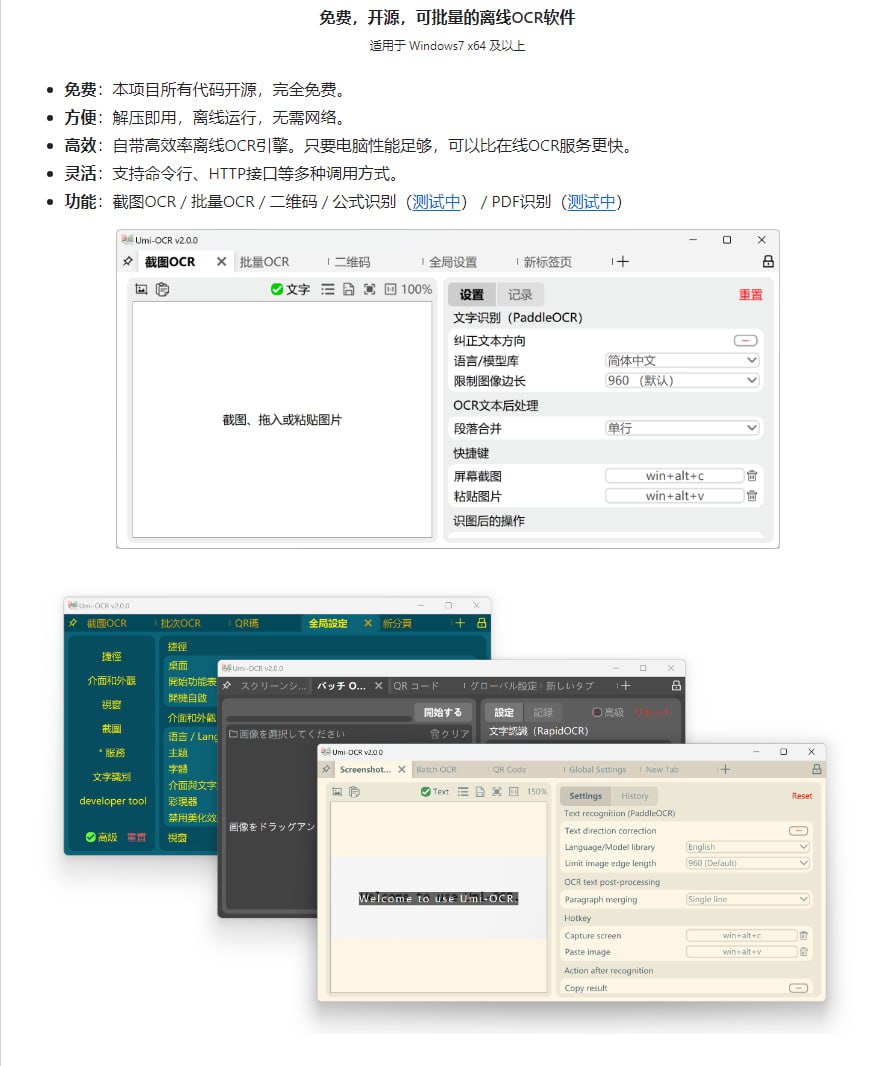
Umi-OCR是一款免费、开源且可离线使用的光学字符识别软件,支持截屏、批量图片与PDF文档识别,具备排除水印、页眉页脚干扰的能力,并内置二维码扫描与生成功能。