Gemma 4 长程逻辑推理能力测试观察
一项针对 Gemma 4 的维吉尼亚密码破解测试显示,该模型在明确指令下可进行长时间深度推理,并在无法解决时选择诚实拒绝而非编造答案,其思维深度具有可调节特性。测试也引发了关于如何更全面评估模型原生推理能力与效率的讨论。
TechFoco

共 5 篇文章,按时间倒序展示。
一项针对 Gemma 4 的维吉尼亚密码破解测试显示,该模型在明确指令下可进行长时间深度推理,并在无法解决时选择诚实拒绝而非编造答案,其思维深度具有可调节特性。测试也引发了关于如何更全面评估模型原生推理能力与效率的讨论。
谷歌低调发布数学专用模型 Aletheia,在国际数学奥林匹克竞赛基准测试中获得 91.9% 的高分。该模型展现出跨领域建立联系的数学发现能力,但其作为高成本智能体系统,目前并未向公众开放,引发了关于前沿 AI 能...

FullFront 是一个针对多模态大语言模型的前端工程基准测试平台,覆盖设计、理解与代码生成三大核心任务,并提供包含图像渲染与多维度指标分析的自动化评估流水线。

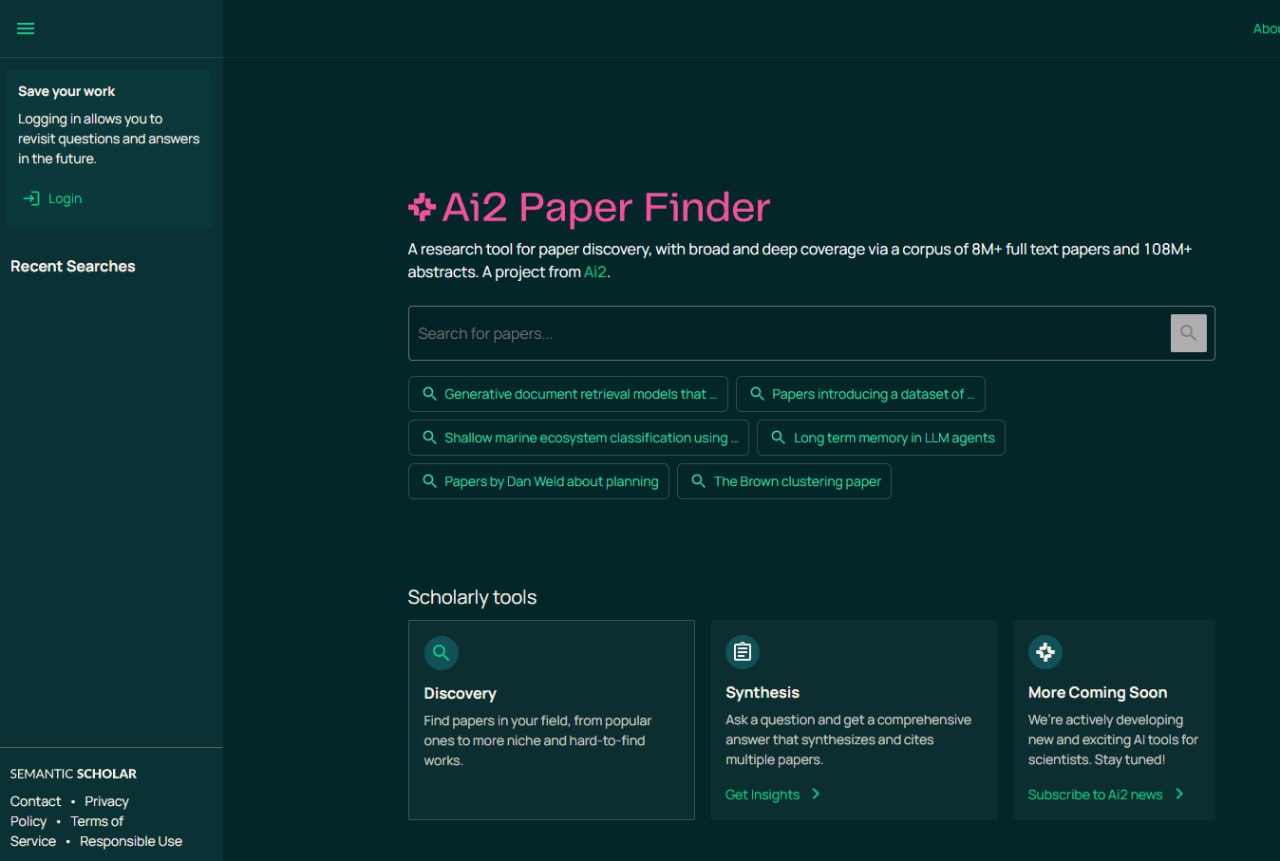
Ai2 Paper Finder 是一个由大语言模型驱动的文献搜索系统,通过模拟多步骤迭代搜索流程来覆盖长尾论文,并提供相关性评估与摘要,在 LitSearch 基准测试中表现优异。
Omni OCR Benchmark 是一个开源基准测试工具,旨在系统评估多模态模型在 OCR 和数据提取任务上的性能。它支持主流模型,并提供 JSON 准确率与文本相似度等关键指标。
