uniOCR:跨平台原生 OCR 工具解析
uniOCR 是一款支持 macOS、Windows 和 Linux 的原生 OCR 工具,通过集成各平台原生 API 与 Tesseract,提供统一接口并利用异步处理提升性能。
光学字符识别(OCR)技术是数字化信息处理的关键环节,其应用场景广泛,从文档电子化到图像信息提取均不可或缺。然而,不同操作系统平台往往采用各自的原生 OCR 引擎,这给需要跨平台部署的开发者带来了接口不统一、性能差异等挑战。uniOCR 项目的出现,旨在为这一领域提供一个系统性的解决方案。

核心内容
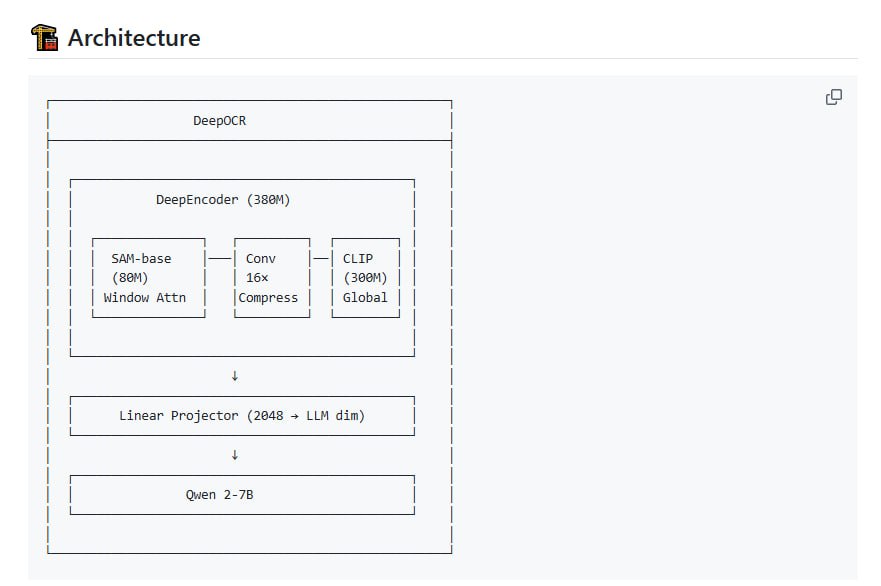
uniOCR 的核心设计目标是实现跨平台的原生 OCR 能力。它主要支持三大桌面操作系统:macOS、Windows 和 Linux。为实现真正的“原生”性能与体验,该项目针对不同平台集成了相应的底层引擎:在 macOS 上调用系统原生的 Vision Kit API;在 Windows 上使用 Windows OCR 引擎;而对于 Linux 或作为跨平台后备方案,则集成了开源的 Tesseract 引擎。
在此基础上,uniOCR 通过封装提供了一套统一的 API 接口。这意味着开发者无需针对不同平台编写多套调用代码,即可使用一致的编程方式访问 OCR 功能,并且能够在不同的底层引擎之间进行相对轻松的切换。
在性能优化方面,uniOCR 采用了异步处理与并行计算机制。这种设计允许工具高效处理批量识别任务,充分利用现代多核处理器的计算能力,从而在识别速度和系统资源利用率上获得提升。
价值与影响
uniOCR 通过抽象和整合不同平台的原生 OCR 能力,降低了开发者在构建跨平台应用时集成文字识别功能的复杂度。其统一接口的设计提升了代码的可维护性和可移植性。异步处理架构则直接回应了实际应用中对于处理效率的需求,特别是在需要处理大量图像或文档的场景下。该项目为需要稳定、高效且易于集成的跨平台 OCR 解决方案提供了一个值得关注的技术选项。