olmOCR:开源高吞吐量文档转换工具
TechFoco 精选
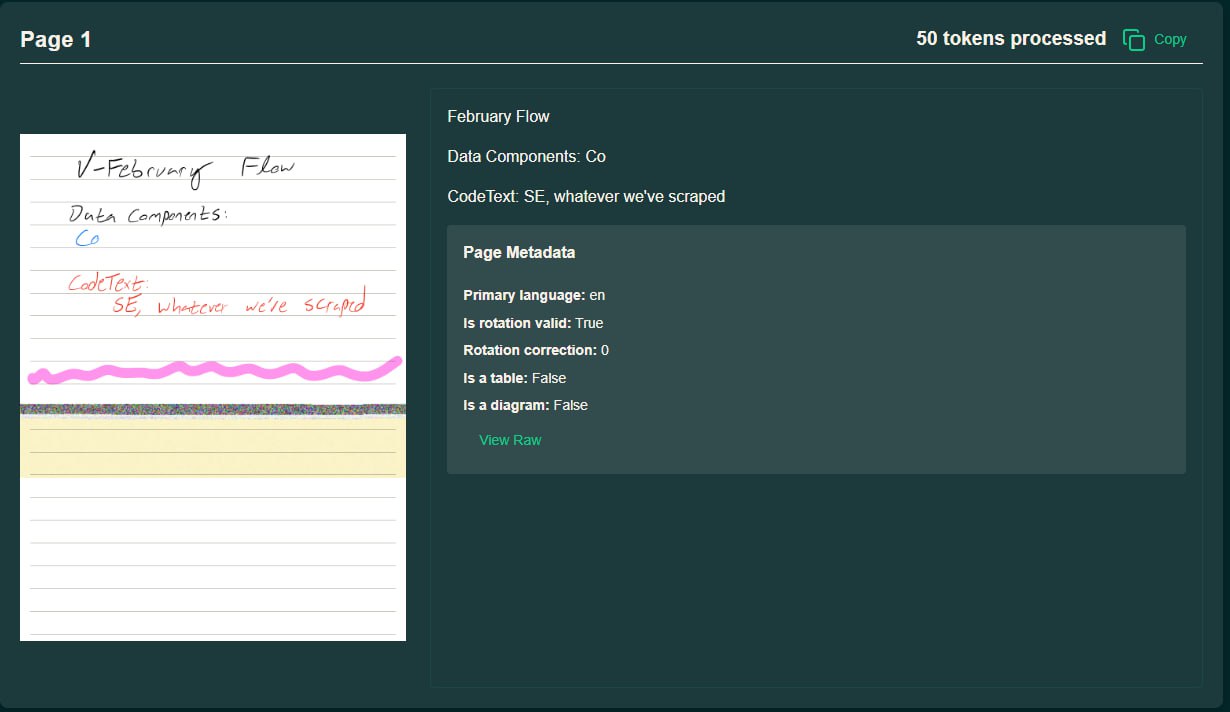
olmOCR 是一款开源工具,专注于将 PDF 等文档高吞吐量转换为纯文本,同时保持自然阅读顺序。它支持表格、公式和手写体等复杂内容,并采用独特提示技术以提高准确性。
在文档数字化和信息提取领域,将 PDF 等格式的文档准确、高效地转换为结构化文本是一项常见需求。传统的 OCR 工具在处理复杂版面、表格或公式时可能面临挑战。近日,由 AllenAI 推出的开源工具 olmOCR 旨在应对这些挑战,专注于高吞吐量的文档转换任务。

核心内容
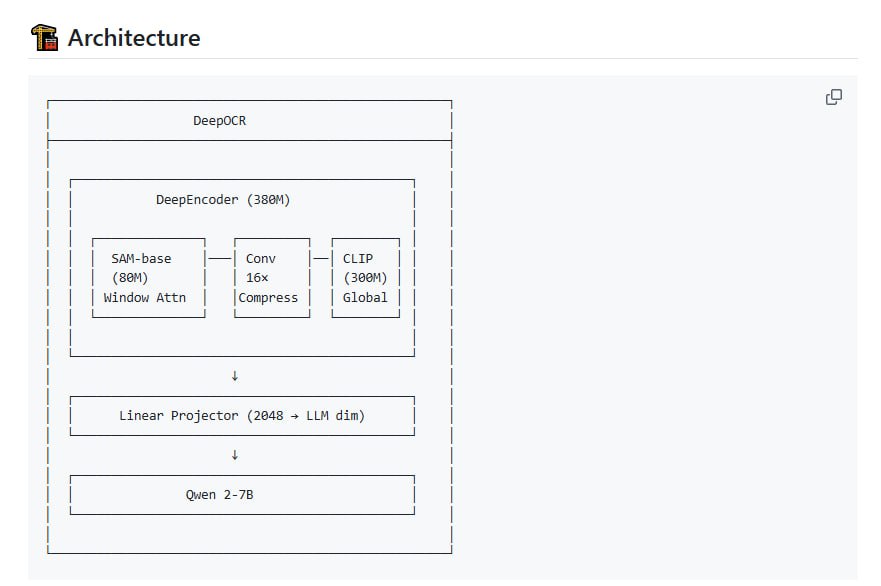
olmOCR 的核心设计目标是实现高吞吐量的文档到纯文本的转换,并在此过程中保持文档的自然阅读顺序。该工具能够处理多种复杂内容,包括表格、数学公式乃至手写体。
其技术特点在于,模型在学术论文、技术文档等参考内容上进行了训练,并采用了一种独特的提示技术。据其技术报告所述,这种技术有助于提升转换的准确性,并减少模型可能产生的“幻觉”或错误输出。
需要指出的是,当前发布的模型主要针对英文文档进行了微调。因此,在处理其他语言的文档时,效果可能无法保证,甚至无法正常工作。
在部署与应用层面,olmOCR 提供了在线演示供用户测试。用户也可以将完整的工具包部署在自有 GPU 上,以实现高效、可扩展的文档处理流程。根据官方估算,以此方式处理的成本约为每百万页 190 美元。
价值与影响
olmOCR 作为一款开源工具,为需要大规模、自动化文档文本提取的场景提供了一个新的选项。其强调的高吞吐量与对复杂版面的支持,使其在学术文献处理、技术文档解析等领域具有潜在应用价值。开源特性也允许社区在此基础上进行进一步的定制与优化。当然,其当前对英文的强依赖性是用户在实际采用前需要考虑的限制条件。
来源:Parry