RAG 专题
共 30 篇文章,按时间倒序展示。
Hindsight™:革命性的 AI Agent 记忆系统
Hindsight™ 是一个 AI Agent 记忆系统,旨在解决传统 RAG 或知识图谱在记忆准确率和长期遗忘上的不足,通过自动提取、多路检索和深度反思,让 AI 真正“学会”。
TechFoco

AI记忆系统突破99%准确率:用Agent完全替代向量数据库
Supermemory团队提出ASMR系统,用多智能体协作替代向量检索,在LongMemEval基准测试上达到99%准确率。该系统通过理解而非相似度匹配来处理记忆任务,架构不依赖外部向量数据库。
TechFoco

无限上下文与RAG:时效性、可追溯性与成本的三重考验
本文探讨了无限上下文与检索增强生成(RAG)的关系,指出RAG的核心价值在于解决知识的时效性、可追溯性和成本控制问题,而非单纯扩展上下文。长上下文模型存在信息关注度衰减问题,两者未来更可能协作而非替代。
TechFoco
Google 发布 Gemini Embedding 2:首个原生多模态嵌入模型
Google 正式发布 Gemini Embedding 2,这是其首个原生多模态嵌入模型。该模型基于 Gemini 架构,首次将文本、图像、视频、音频和文档统一映射到一个共享嵌入空间,打破了传统模态壁垒,并简化了...
TechFoco

OpenRAG:集成 Langflow 与 OpenSearch 的智能文档检索平台
OpenRAG 是一个集成了 Langflow、Docling 和 OpenSearch 的 Retrieval-Augmented Generation 平台,旨在实现智能问答和文档搜索。它提供一键安装、多文档索...
TechFoco
Ruflo:专为 Claude 打造的智能体编排平台
Ruflo 是一个专为 Claude 设计的开源智能体编排平台,支持分布式多智能体协作、RAG 集成和企业级工作流管理,适合 AI 开发者和企业用户。
TechFoco

Prompt Engineering 的演变:从技巧到系统思维
本文探讨了 Prompt Engineering 的现状,指出早期依赖特定“魔法短语”的技巧已过时,其核心思维方式正融入 RAG、Agentic 工作流等更高级的系统设计中。
TechFoco

OpenViking:字节跳动开源的AI Agent上下文数据库
字节跳动开源了专为AI Agent设计的上下文数据库OpenViking,旨在解决传统RAG在上下文管理、检索和可观测性方面的挑战。
TechFoco

无需向量嵌入的RAG新思路:PageIndex与文档树检索
开源项目PageIndex提出了一种基于文档树结构而非向量嵌入的RAG实现方法,在结构化文档检索上表现出高准确率,但也面临处理单文档、推理速度及扩展性等挑战。
TechFoco

NotebookLM:被低估的AI学习与知识管理工具
本文介绍谷歌的NotebookLM工具,它基于用户上传的文档进行信息提取与生成,提供闪卡、思维导图等学习辅助功能,并探讨其支持个性化学习的价值。
TechFoco

如何将RAG幻觉率降至1-2%:四层防线解析
一位开发者分享了其实战经验,通过提升文档解析质量、采用混合检索、进行激进重排序以及设置严格的系统提示这四层防线,将RAG系统的幻觉率从常见的两位数显著降低至1-2%。
TechFoco

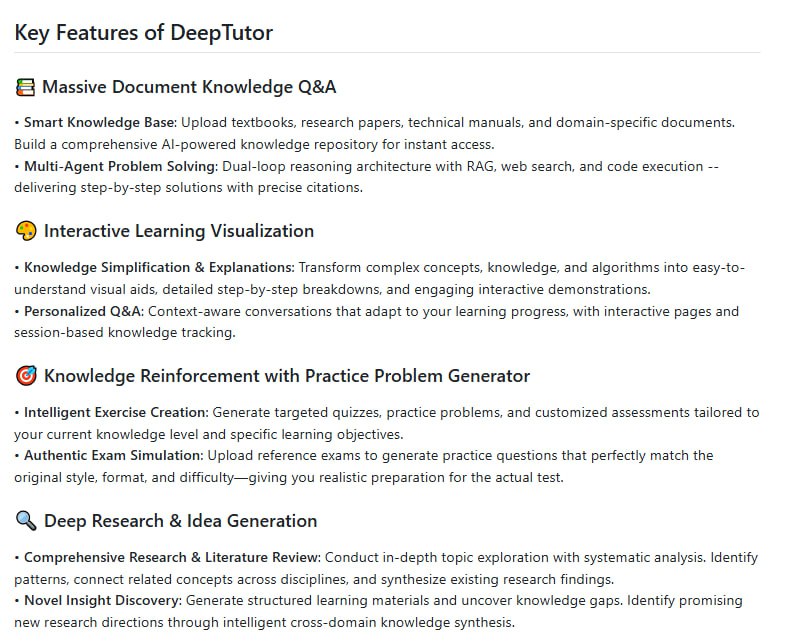
DeepTutor:香港大学开源 AI 学习助手
DeepTutor 是香港大学开源的一站式 AI 学习助手,整合了文档问答、知识可视化、练习生成和深度研究功能,支持本地部署,旨在提升学习与研究的效率。
TechFoco
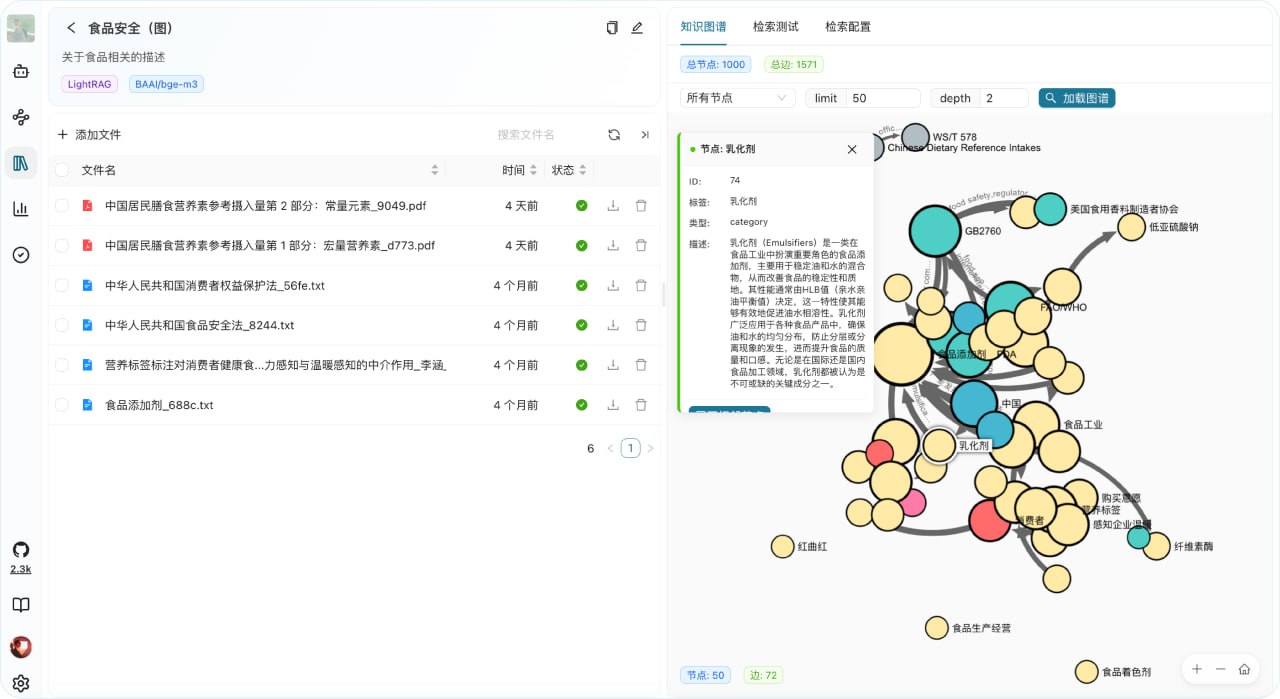
Yuxi-Know:基于 LightRAG 的 RAG 与知识图谱平台
Yuxi-Know 是一个基于 LightRAG 构建的 RAG 知识库和知识图谱平台,融合了 RAG 与知识图谱技术,基于 LangGraph v1、Vue.js、FastAPI 等技术栈,提供全套智能体开发套件。
TechFoco
Local Voice AI:全栈本地化语音助手开源项目
Local Voice AI 是一个通过 Docker 容器化技术整合语音识别、大模型推理、语音合成及 RAG 检索的全栈开源项目,提供了一套完整的本地化语音助手解决方案,所有处理均在本地完成。
TechFoco

《The Context Engineering Guide》:超越上下文窗口的智能系统设计
本文基于《The Context Engineering Guide》电子书,阐述了上下文工程的核心在于设计动态、精准的信息管理系统,而非单纯扩大模型上下文窗口。它涉及代理、记忆系统、检索增强等模块的编排,是构建稳...
TechFoco

Gemini API File Search:全托管 RAG 系统
Gemini API 新推出的 File Search 是一个全托管的检索增强生成系统,能自动处理文件存储、分块、嵌入和检索,简化了基于文档的智能问答应用开发。其成本结构友好,支持多种文件格式,并已在多个实际场景中...
TechFoco
Vector RAG 系统构建流程详解
本文系统梳理了构建 Vector RAG 系统的九个核心步骤,包括数据采集、文本切分、向量嵌入、存储检索、流程编排、模型生成、监控与优化,并列举了各环节的常用工具与技术选型。
TechFoco

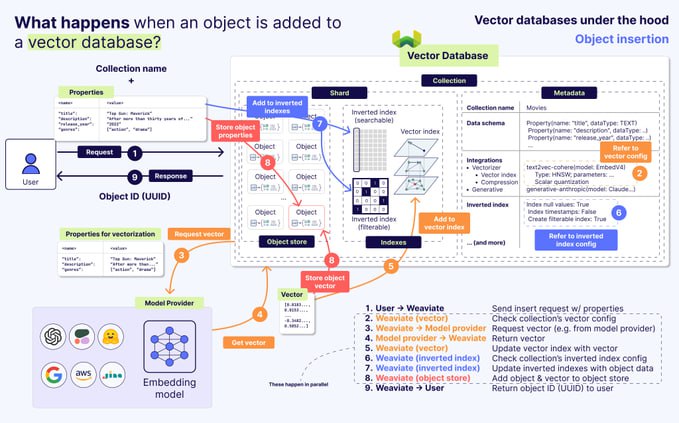
向量数据库工作原理详解:从嵌入到 HNSW 索引
本文解析了向量数据库的核心工作流程,包括通过向量嵌入将数据转化为高维空间坐标,利用 HNSW 等索引技术解决海量向量相似性搜索的挑战,并阐述了其在语义搜索和 RAG 等场景中的基础价值。
TechFoco
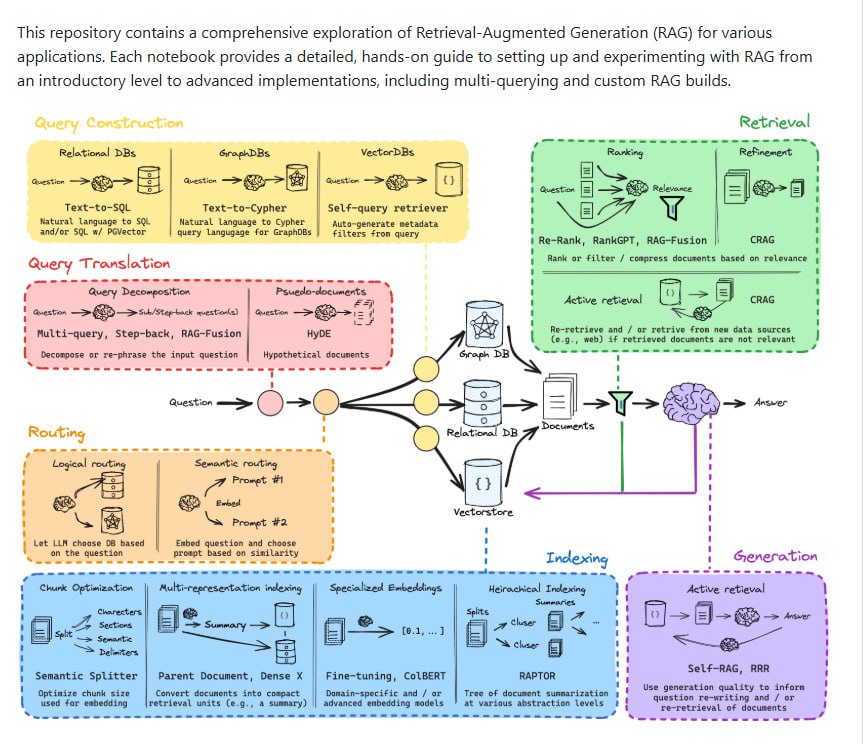
bRAG-langchain:系统性掌握 RAG 技术的开源指南
本文介绍 bRAG-langchain 开源项目,该项目通过一系列 Jupyter Notebook 提供了从查询构建、检索优化到生成环节的完整 RAG 技术栈实操指导,旨在帮助开发者系统性地掌握检索增强生成技术。
TechFoco