ChatGPT 类系统的工作原理解析
本文解析了类似 ChatGPT 的系统如何工作,主要分为模型训练与用户问答两个核心流程。训练阶段包括预训练和基于人类反馈的强化学习微调;问答流程则重点阐述了内容审核机制对输入与输出的双重安全保障。
以 ChatGPT 为代表的大型语言模型已广泛应用于对话、问答等场景。理解其背后的工作机制,有助于我们更清晰地认识这类系统的能力边界与实现路径。
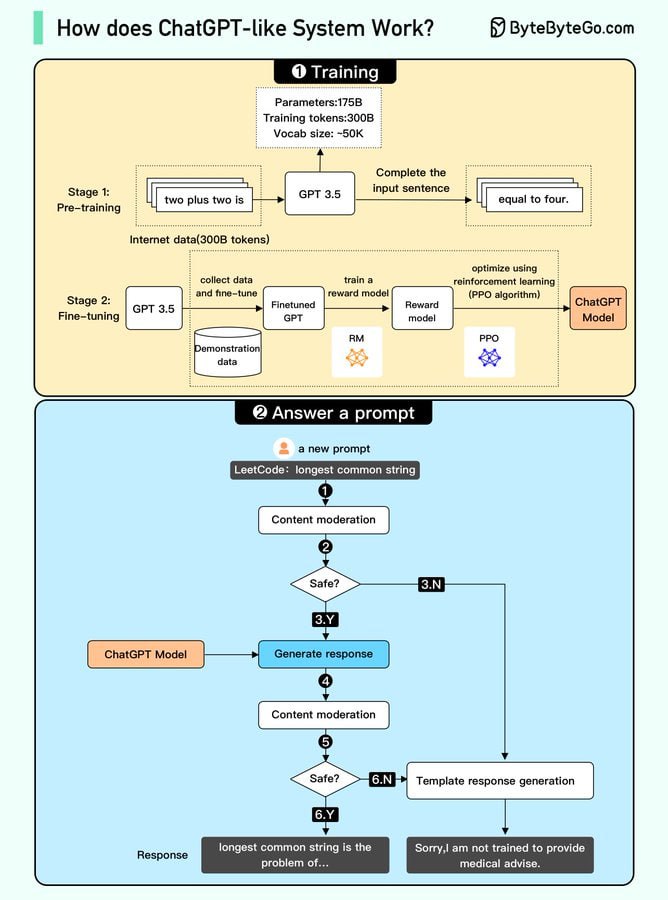
类似 ChatGPT 的系统工作流程可清晰划分为模型训练与在线问答两大部分。
在训练阶段,系统首先进行预训练。此阶段使用海量互联网文本数据训练一个仅解码器的 Transformer 模型(如 GPT 系列),目标是让模型学会根据上文预测下一个词,从而掌握语言的语法与语义模式。完成预训练的模型具备文本生成能力,但尚无法进行高质量的指令跟随与问答。
随后是关键的微调阶段,旨在将通用语言模型转化为可控、有用的对话助手。该阶段通常包含三个步骤:首先进行监督微调,使用人工编写的优质问答数据对模型进行训练,使其初步学会根据问题生成答案。接着,训练一个奖励模型,通过让人类标注员对不同答案进行排序,教会模型区分回答质量的高低。最后,利用强化学习算法(如 PPO)对模型进行优化,使其生成的答案能获得奖励模型给出的更高评分,从而不断提升回答的相关性与准确性。
在用户实际提问的在线问答流程中,系统会执行严格的内容审核以确保安全。当用户输入问题后,内容审核组件首先对输入进行过滤,拦截违反安全准则的内容。通过审核的问题才会被送入 ChatGPT 模型生成回答。模型生成回答后,内容审核会再次对输出内容进行安全检查。只有输入与输出均通过审核,回答才会最终呈现给用户;若任一环节未通过,系统则会启用预设的安全模板进行回复。
这种结合了多阶段训练与双重内容审核的架构设计,是 ChatGPT 类系统能够同时保持强大语言能力与可控安全输出的关键。它明确了从海量数据中学习通用知识,到通过人类反馈进行精细化对齐,再到部署时进行实时风险控制的全链路技术方案,为构建可靠、实用的大语言模型应用提供了清晰的工程范式。





