Crawlee:功能强大的现代爬虫工具
TechFoco 精选
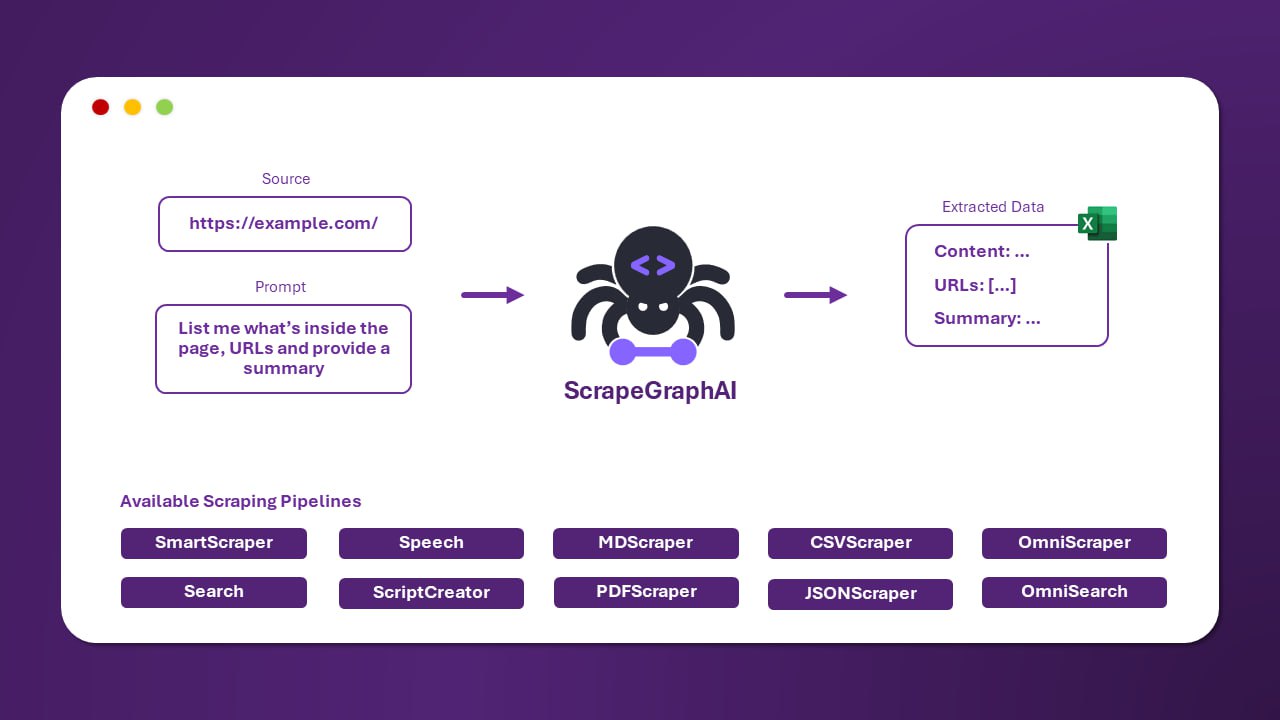
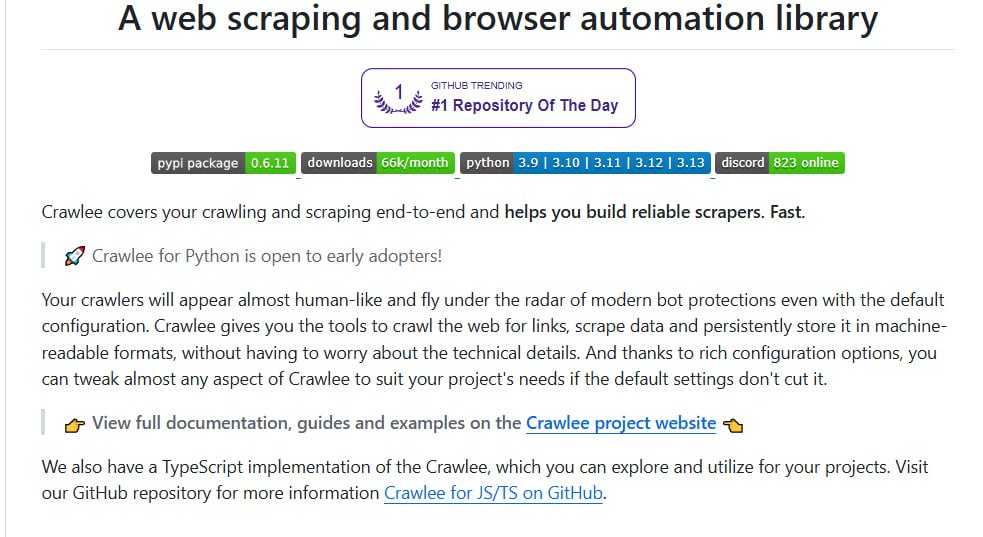
Crawlee 是一个技术栈较新的爬虫工具,支持 HTTP 和基于真实浏览器的 Headless 两种模式,内置 DOM 解析库,并具备反屏蔽与模拟人类指纹机制,以降低被封禁风险。
在数据采集领域,爬虫工具的选择直接影响着开发效率和数据获取的稳定性。随着 Web 技术的演进,特别是 JavaScript 渲染页面的普及,对爬虫工具提出了更高的要求。Crawlee 作为一个技术栈较新的爬虫工具,旨在应对这些挑战,提供一套功能强大的解决方案。
核心内容
Crawlee 的核心设计兼顾了灵活性与自动化。它能够根据运行环境的电脑资源状况,自动切换并发请求的数量,从而优化性能与资源占用。在解析网页内容方面,工具内置了 Cheerio 和 JSDOM 这两个流行的 DOM 解析库,使得分析页面结构变得方便快捷。
该工具主要提供两种工作模式以适应不同场景。HTTP 模式适用于获取静态 HTML 内容。而 Headless 模式则基于 Puppeteer 和 Playwright 等真实浏览器模拟技术,能够完整执行页面中的 JavaScript,从而可靠地爬取动态渲染的内容。
为了应对日益严格的反爬虫措施,Crawlee 集成了特殊的反屏蔽机制以及模拟人类指纹的技术。这些特性旨在使爬虫行为更接近真实用户,从而显著降低被目标网站封禁的概率。
价值与影响
Crawlee 通过整合现代浏览器自动化技术与智能的反检测策略,为开发者提供了一个相对可靠的数据采集工具。其自动资源管理功能减轻了开发者在并发控制上的负担,而双模式设计则覆盖了从静态页面到复杂单页应用的数据抓取需求。这些特性使其在需要处理 JavaScript 渲染内容且对抗反爬虫策略的项目中,可能成为一个值得考虑的技术选项。
来源:黑洞资源笔记