Scrapling:自适应网页结构变动的 Python 爬虫框架
Scrapling 是一个开源 Python 爬虫框架,具备自适应网页结构变动的能力,覆盖从单请求到大规模爬取,内置多种抓取器与反爬策略,并提供 AI 辅助提取功能。
TechFoco

共 11 篇文章,按时间倒序展示。
Scrapling 是一个开源 Python 爬虫框架,具备自适应网页结构变动的能力,覆盖从单请求到大规模爬取,内置多种抓取器与反爬策略,并提供 AI 辅助提取功能。
Vercel Labs 开源了 agent-browser,这是一个基于 Rust 的浏览器自动化 CLI 工具,专为 AI 代理设计,支持网页操作、数据抓取和自动化测试。

开源工具 Agent Reach 旨在解决 AI Agent 访问网络内容时遇到的 API 付费、平台封锁等难题。它支持 Twitter、YouTube、Reddit 等多平台,具备一键安装、可插拔架构及本地 Co...

开源项目 PinchTab 是一款高性能的浏览器自动化桥接及多实例调度工具,通过统一的 HTTP 服务接口控制 Chrome 浏览器,支持并行、隐身和低资源消耗,适用于智能爬虫、自动化测试等场景。

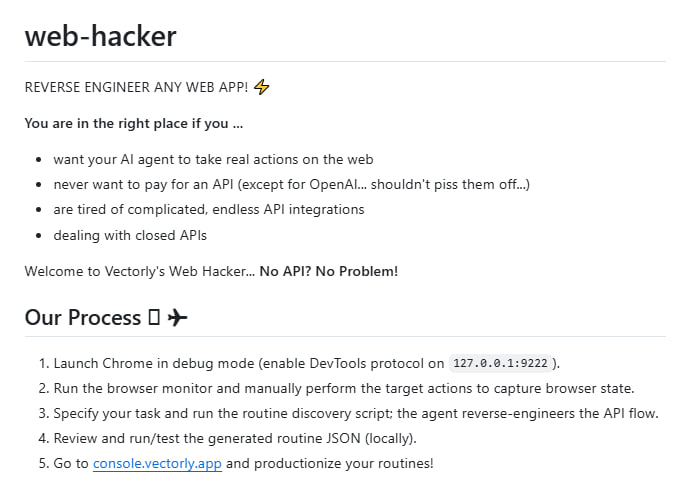
Web Hacker 是一个开源工具,旨在解决在没有官方 API 的情况下实现网页自动化的问题。它通过监控浏览器调试模式下的操作,利用 AI 分析网络流量和状态,自动提取可重复的 API 调用流程,并将其转化为标准...
Spider Creator 是一款结合浏览器操作录制与大语言模型的工具,可通过自然语言描述自动生成 Playwright 爬虫脚本,旨在简化重复性数据采集任务的开发流程。

AI Web Scraper 是一款利用自然语言实现无代码网页数据抓取与工作流自动化的工具。它支持操作追踪回放,并广泛集成 n8n、Make 等自动化平台,旨在降低数据自动化门槛。

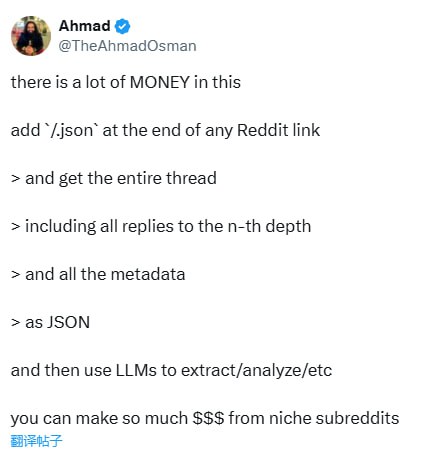
本文介绍一种无需登录即可抓取 Reddit 完整讨论数据的技术方法:在链接后添加 /.json 后缀。该方法可直接获取深度嵌套的原始数据和元信息,结合 LLM 分析,适用于市场研究、内容策划等多种场景。
Get Jobs 是一款基于 Python 的开源工具,旨在通过自动化技术帮助求职者高效投递简历。它支持 Boss 直聘等五大主流招聘平台,集成了 AI 智能匹配、定时投递、智能过滤等功能,以优化求职流程并提升效率。

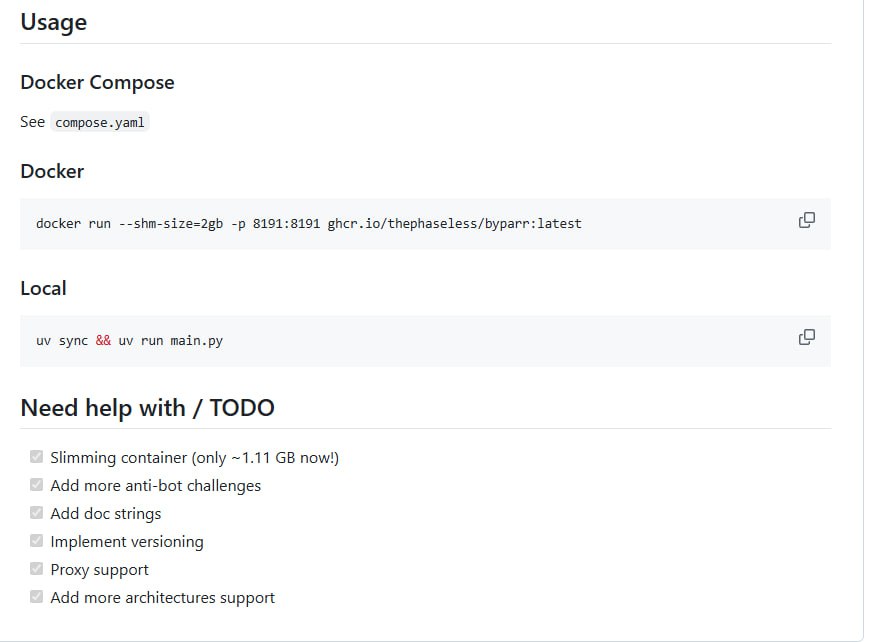
Byparr 是一款基于 seleniumbase 与 FastAPI 的工具,旨在通过模拟浏览器行为生成有效的 HTTP Cookie 和 Headers,以应对 Cloudflare 等反爬机制。它提供 Doc...
LLM API Engine 是一个开发工具,允许开发者通过自然语言描述快速生成和部署 AI 驱动的 API。它结合了大型语言模型与网络爬虫技术,能够自动从网站提取结构化数据,并支持部署到 Vercel、AWS L...
