DeepSeek R1 模型构建指南
TechFoco 精选
本文介绍了从 Qwen 基础模型出发,通过 GRPO 算法、监督微调及强化学习,逐步构建并优化 DeepSeek R1 模型推理能力的完整流程。
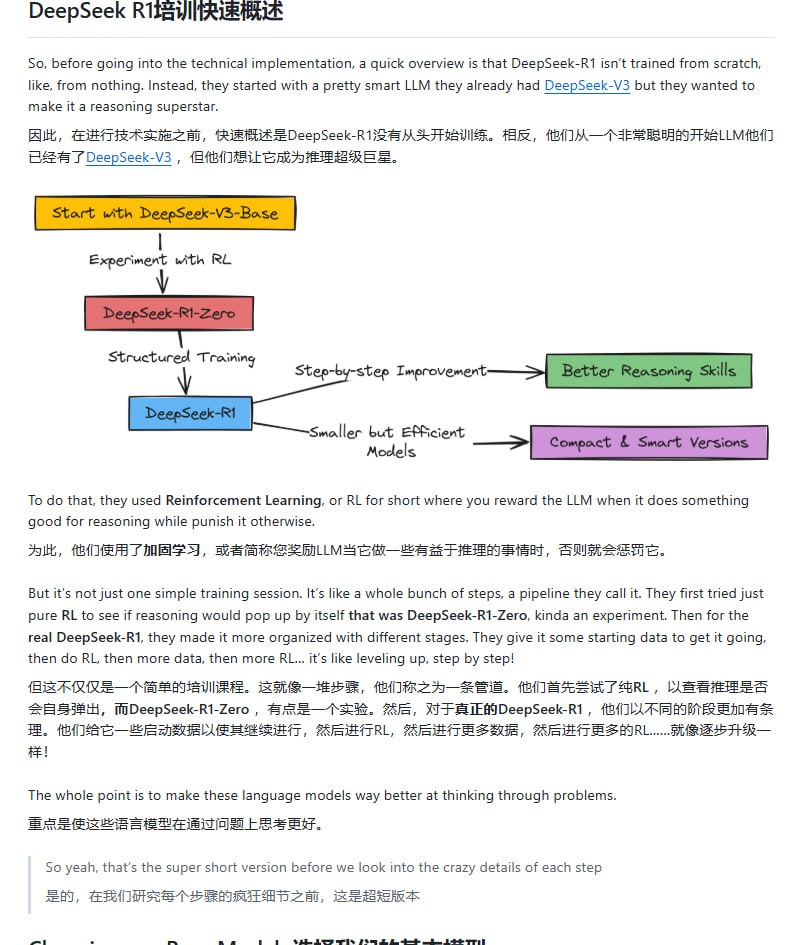
构建具备强大推理能力的大语言模型是当前人工智能领域的重要方向。DeepSeek R1 作为一个专注于推理的模型,其构建过程融合了多种前沿的训练技术。开源社区提供了从基础模型到最终推理模型的完整实现路径,为研究者和开发者提供了清晰的实践参考。
核心内容
该构建流程以 Qwen 模型作为起点。首先,应用 GRPO 算法对模型进行初步训练,旨在优化其基础推理能力。这一步骤为后续的精细调整奠定了基础。
随后,流程进入监督微调阶段。通过 Supervised Fine-Tuning,模型在特定任务数据上进行学习,以提升其输出的准确性和语言一致性。
为进一步增强模型的复杂推理能力,流程还引入了改进的强化学习方法。这一阶段旨在让模型学会在更开放、多步骤的推理任务中进行决策和优化。
整个流程提供了从数据处理、模型训练到评估的完整代码实现。为了便于理解,项目还包含了详细的训练过程说明和手绘的流程图,降低了实践门槛。
价值与影响
该实现方案的价值在于提供了一套可复现的、端到端的模型构建方法论。它将 GRPO、监督微调和强化学习等技术串联起来,系统性地展示了如何将一个通用基础模型转化为专精于推理的模型。对于希望深入理解大语言模型训练,特别是推理能力优化机制的研究人员和工程师而言,这份材料具有直接的参考意义。它有助于推动相关技术在更广泛场景下的应用与探索。