Fast-Powerful-Whisper-AI-Services-API 项目解析
本文介绍了一个基于 FastAPI 和 asyncio 构建的高性能异步 Whisper 语音识别服务 API。该项目支持分布式处理、内置多平台爬虫,并集成了 ChatGPT,旨在应对大规模自动语音识别场景。
随着语音识别技术在媒体处理、内容分析等领域的广泛应用,构建一个能够处理高并发、支持分布式部署的服务接口成为实际需求。Fast-Powerful-Whisper-AI-Services-API 项目应运而生,它旨在提供一个强大、高性能的异步 Whisper 服务 API,以满足大规模自动语音识别场景的需要。
核心内容
该项目基于 Python 3.11 的 asyncio 异步特性进行构建,所有模块均采用异步设计,以提升请求处理效率和系统的高并发能力。其核心架构与功能主要体现在以下几个方面。
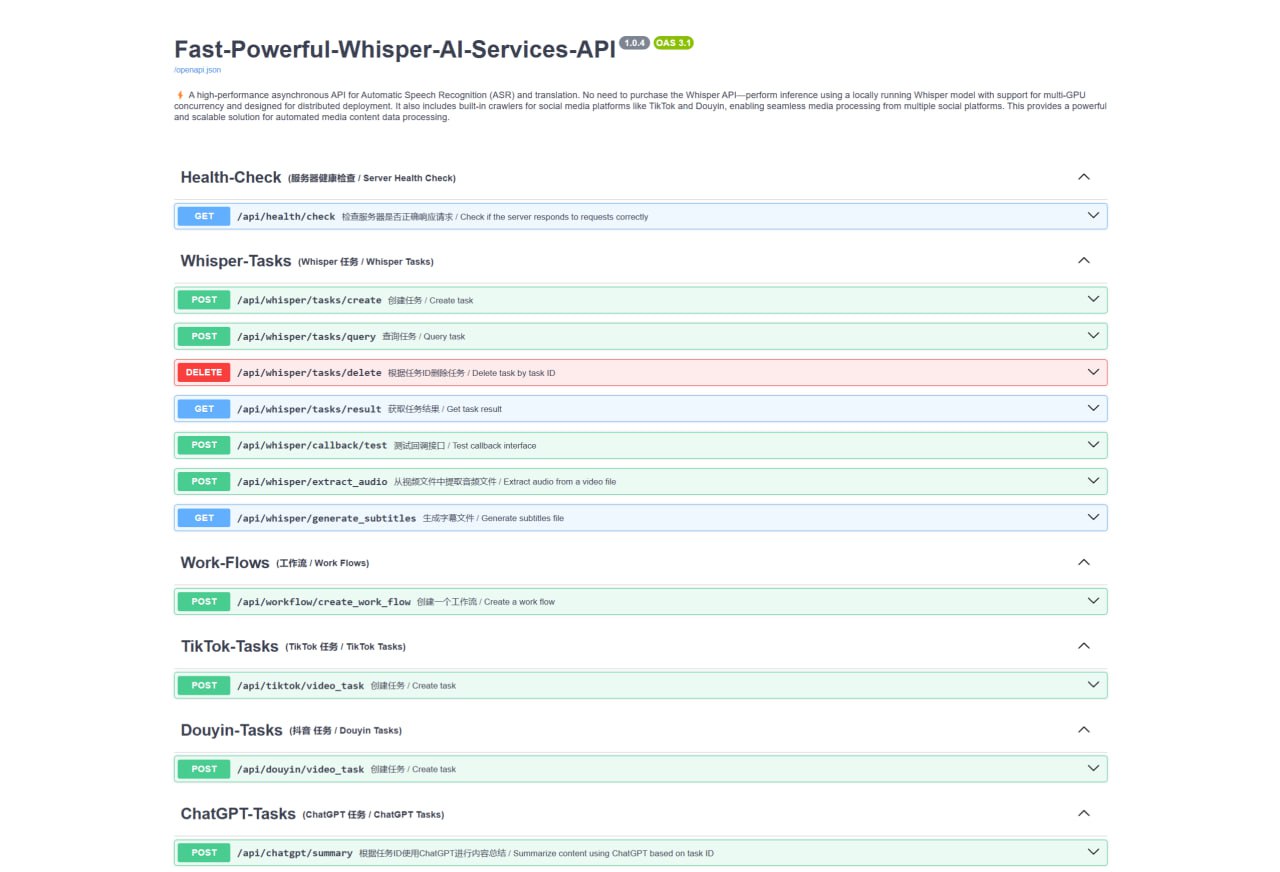
项目采用 FastAPI 框架,自动生成了交互式 Swagger UI 文档,便于接口测试与使用。在模型层面,它集成了 OpenAI Whisper 及其高性能实现 Faster Whisper,并默认使用最新的 large-v3 模型以保证识别准确率。项目实现了一个异步 AI 模型池,在线程安全的前提下支持多模型实例的并发处理。在支持 CUDA 且拥有多 GPU 的环境中,模型池可通过智能加载机制将模型分配至不同 GPU,实现负载均衡与任务自动分配,但在单 GPU 场景下无法提供并发功能。
为支持分布式部署,项目设计使用统一的数据库(支持 MySQL 和 SQLite)作为任务源与结果存储,未来计划与 Kafka 集成以实现实时数据流处理。此外,项目内置了异步网络爬虫模块,目前支持从抖音和 TikTok 平台通过视频链接自动采集并处理媒体内容,未来计划扩展至更多社交平台。项目已集成 ChatGPT,允许用户基于语音识别结果进行内容总结等交互操作。
在功能实现上,项目提供了完整的任务管理 API。用户可以通过上传文件或指定文件链接来创建语音识别或翻译任务,并可设置任务优先级、指定结果回调地址。系统支持细粒度的 Whisper 解码参数配置。其他功能包括任务查询与删除、结果获取、从视频中提取音频、生成 SRT 或 VTT 格式字幕文件等。项目规划了工作流与组件化设计(待实现),未来允许用户通过 JSON 定义或 Python 编写自定义组件,构建事件驱动的智能处理流程。
价值与影响
Fast-Powerful-Whisper-AI-Services-API 项目通过其异步、分布式的设计,为处理大规模语音转文本任务提供了一个高性能的解决方案。其价值在于将高效的 Whisper 模型、便捷的爬虫数据采集、灵活的任务管理以及未来可扩展的工作流系统整合于一体。
该项目适用于多种场景,包括需要对网络或本地大量媒体文件进行转录、分析、翻译和字幕生成的媒体数据处理;通过 API 与其他系统集成实现自动化任务流;结合异步爬虫进行动态数据采集与分析;以及在分布式计算环境中有效利用零散算力。项目的开源特性也为开发者社区提供了一个可参考、可扩展的高性能语音识别服务实现范例。