CyberScraper 2077:LLM 驱动的精准网络爬虫
TechFoco 精选
CyberScraper 2077 是一款利用大型语言模型(LLM)进行驱动的网络爬虫工具,旨在提升网页数据提取的效率和准确性。
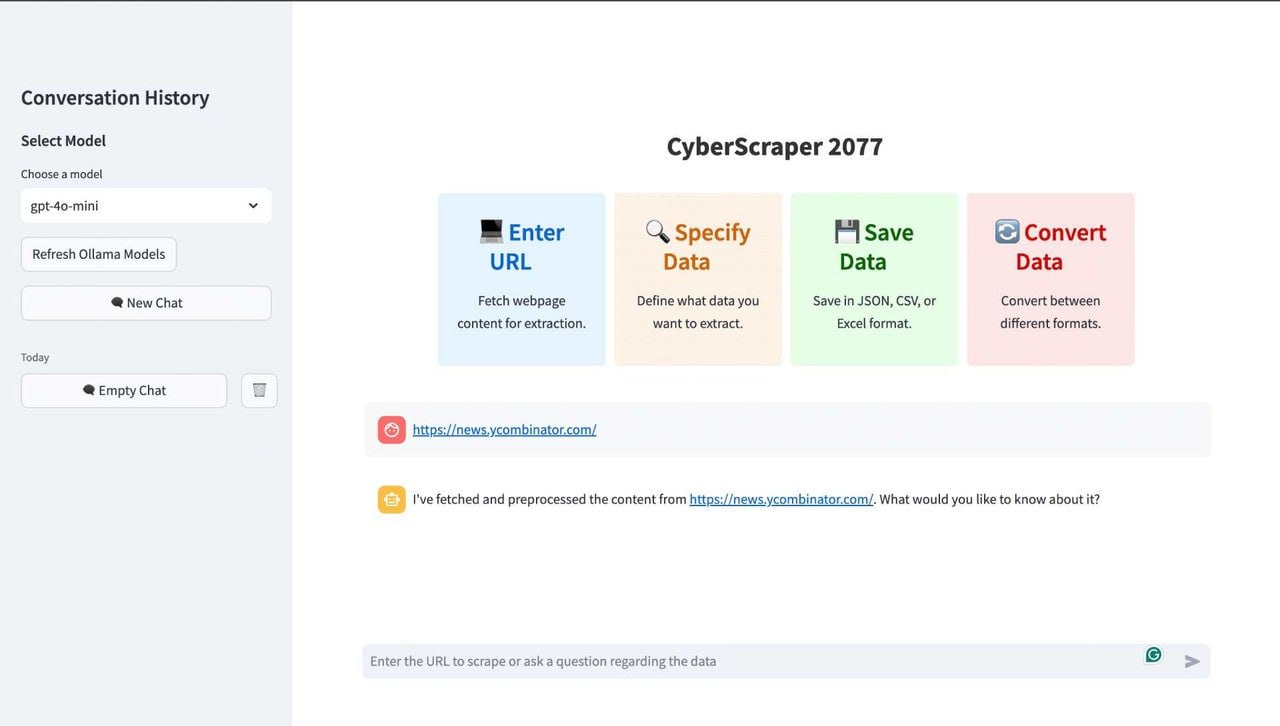
在数据驱动的时代,高效、精准地从互联网获取结构化信息是许多技术应用的基础。传统的网络爬虫依赖于预设的规则或模式匹配来解析网页,在面对复杂、动态变化的网页结构时,其灵活性和准确性往往面临挑战。近年来,大型语言模型(LLM)在理解和生成自然语言方面展现出强大能力,为自动化数据提取任务提供了新的思路。
核心内容
CyberScraper 2077 是一个将 LLM 能力应用于网络爬虫领域的工具。其核心在于利用 LLM 对网页内容进行语义理解,而非仅仅依赖固定的 HTML 标签或 XPath 路径。这种方法允许工具更智能地识别和提取目标数据,即使网页的布局或代码结构发生变化,也能保持较高的提取成功率。
该工具的设计目标是实现高效且精准的数据抓取。通过 LLM 对上下文的理解,它可以更准确地定位所需信息,减少无关数据的干扰,从而提升整体爬取效率。
价值与影响
将 LLM 集成到网络爬虫流程中,代表了数据采集技术的一个发展方向。它有望降低构建和维护复杂爬虫规则的技术门槛,使非专业开发者也能更便捷地获取网络数据。对于需要从大量异构网页中持续、稳定提取信息的研究或商业场景,此类工具可能提供更可靠的解决方案。然而,其实际效能、处理速度以及对不同网站结构的泛化能力,仍需在具体应用中进一步验证。




