小红书开源 FireRedASR 语音识别模型
TechFoco 精选
小红书开源了 FireRedASR 语音识别模型,提供 LLM 和 AED 两种架构,分别针对高质量转写和普通应用场景,在普通话基准测试中表现优异。
语音识别(ASR)技术是连接语音与数字世界的关键桥梁,其应用已深入日常生活与专业领域。近期,小红书开源了其最新的语音识别模型 FireRedASR,该模型在公共普通话 ASR 基准测试中达到了新的最佳水平,并提供了两种不同的架构设计以适应多样化的应用需求。
核心内容
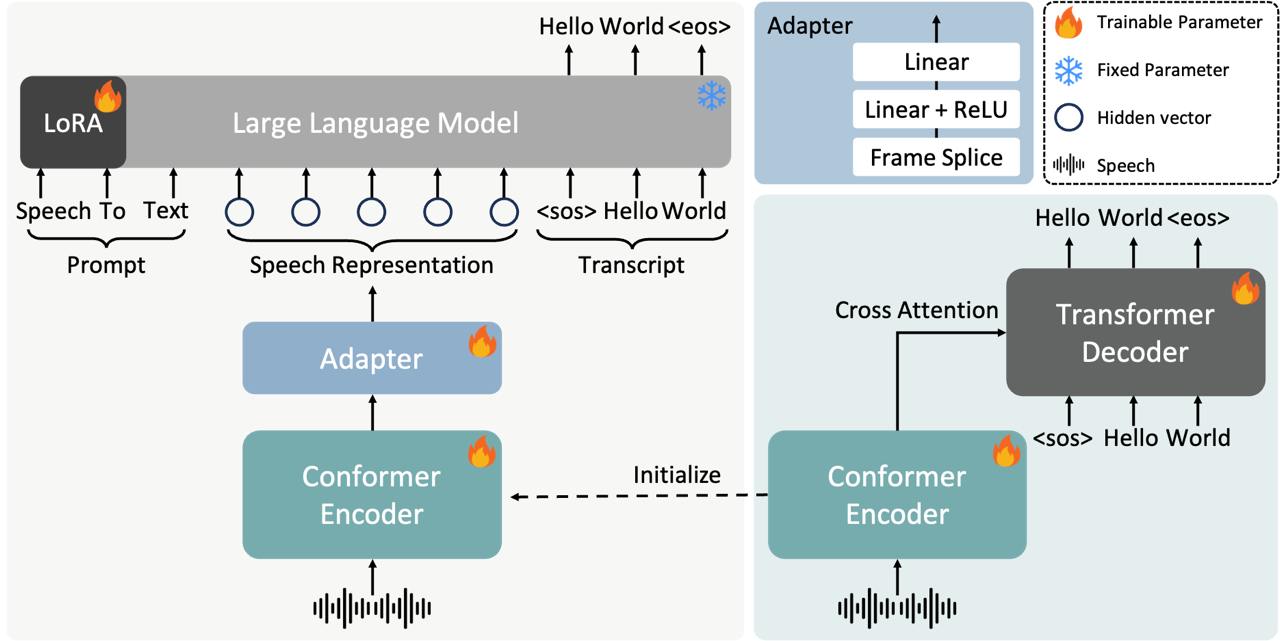
FireRedASR 模型擅长识别中英文、方言及歌词,展现了较强的泛化能力。模型提供了两种核心架构版本:
- LLM 架构版:参数量为 8.3B,旨在实现高识别准确率。它支持无缝的端到端语音交互,适合对转写质量要求极高的场景。
- AED 架构版:参数量为 1.1B,设计上更注重在性能与效率之间取得平衡,适合资源受限或对实时性要求较高的普通应用场景。
价值与影响
FireRedASR 的开源为语音识别社区提供了新的技术选项。其双架构设计允许开发者和研究者根据具体场景在精度与效率之间进行灵活选择。模型在基准测试中的优异表现,也为推动中文及多语言、多方言场景下的语音识别技术进步提供了参考。
来源:Parry