markdown_crawler:专为 LLM 设计的文档爬虫
TechFoco 精选
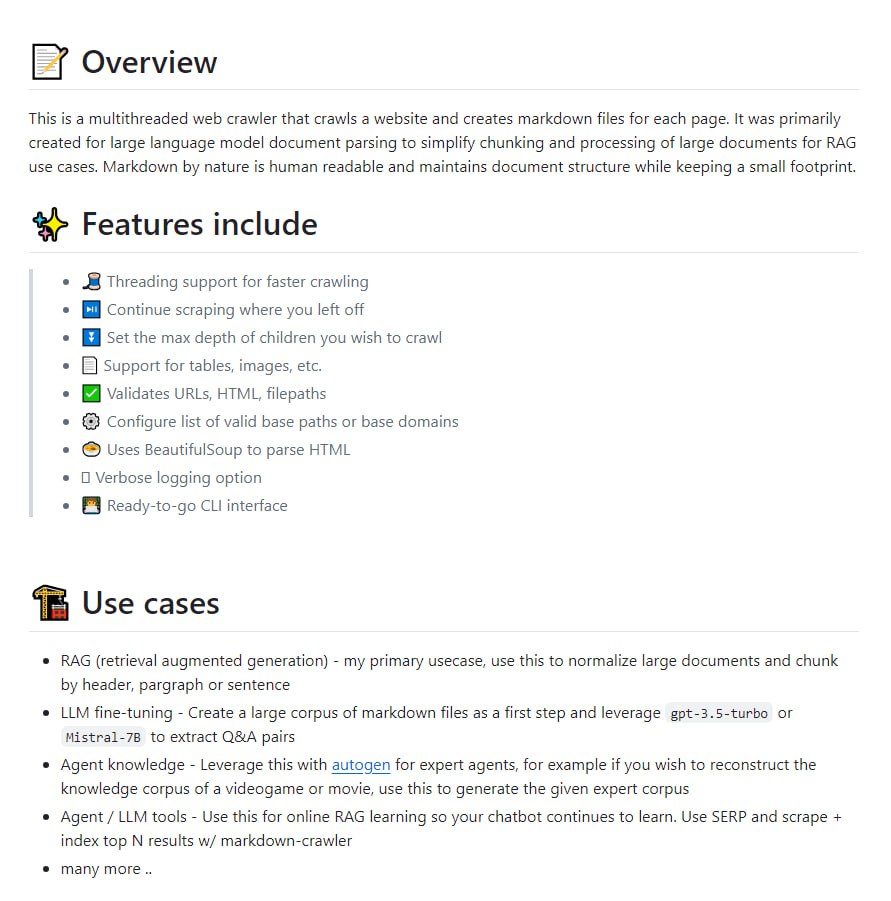
markdown_crawler 是一个多线程网络爬虫工具,能够递归爬取网站内容并为每个页面生成 Markdown 文件,其设计目标是为大型语言模型的文档解析任务提供结构化的数据源。
在人工智能领域,特别是大型语言模型(LLM)的训练与应用中,获取高质量、结构化的文档数据是一个关键环节。传统的网页爬虫工具虽然能够抓取内容,但往往无法直接输出适合 LLM 进行高效解析和学习的格式。因此,专门针对此类需求设计的工具应运而生。
核心内容
markdown_crawler 是一个多线程网络爬虫工具。它的核心功能是递归地爬取指定网站的所有页面。在爬取过程中,该工具会为每一个获取到的网页内容创建一个对应的 Markdown 文件。这种设计使其能够将非结构化的网页内容,转换为结构化的 Markdown 文本。
该工具明确针对大型语言模型的文档解析需求进行优化。通过生成 Markdown 格式的文件,它能够更好地保留文档的层级结构、链接和基本格式,为后续的模型训练或文档分析提供便利。
价值与影响
markdown_crawler 的出现,为需要大规模文档数据进行 LLM 相关研究和开发的技术团队提供了一个实用工具。它简化了从互联网获取和预处理文档数据的工作流,将原始网页转换为更易于语言模型处理的 Markdown 格式。这有助于提升文档解析任务的效率和数据质量,支持知识库构建、模型微调等多种应用场景。





