crawlist:网页列表爬取的通用解决方案
TechFoco 精选
crawlist 是一个托管于 GitHub 的开源项目,旨在为爬取网页列表数据提供一个通用的解决方案,由开发者 WwwwwyDev 创建。
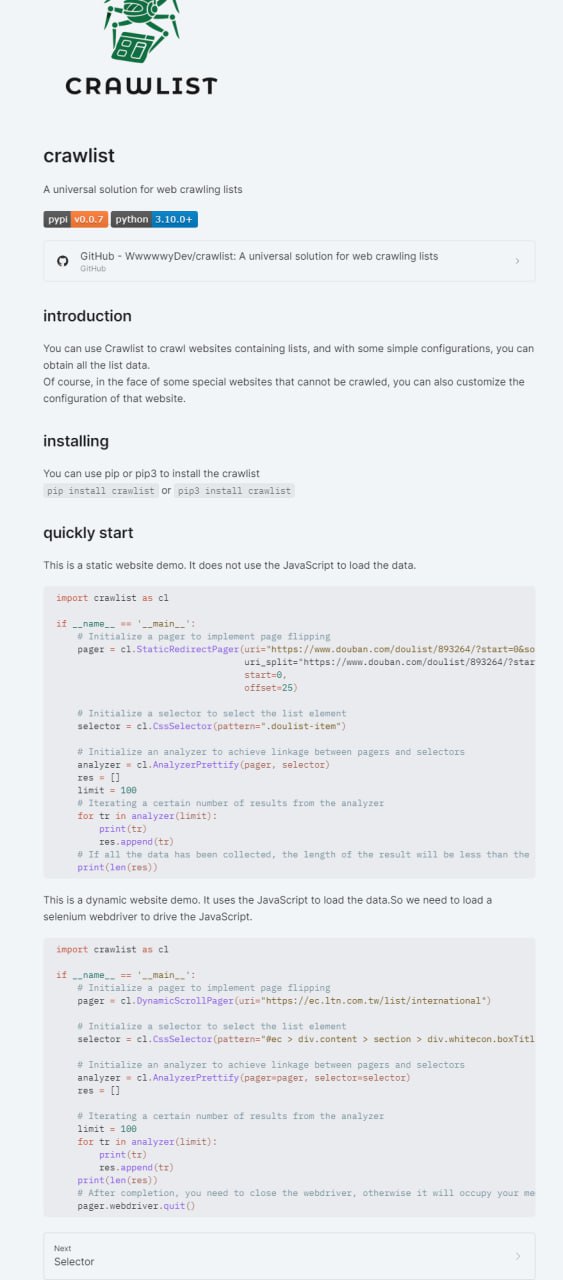
在数据采集和网络爬虫领域,针对特定网站或列表页面的爬取需求十分常见。然而,传统的爬虫脚本往往与目标网站的结构深度耦合,缺乏通用性和可复用性。crawlist 项目的出现,正是为了应对这一挑战,旨在提供一个用于爬取网页列表的通用解决方案。
核心内容
crawlist 是一个托管在 GitHub 上的开源项目,由开发者 WwwwwyDev 创建并维护。其核心设计目标是抽象出网页列表爬取的通用逻辑,从而减少针对不同网站重复开发爬虫的工作量。该项目试图通过一套标准化的接口或方法,来处理不同结构网页中的列表数据抽取问题。
价值与影响
对于需要进行批量数据采集的开发者和研究人员而言,crawlist 提供了一种思路,即通过构建通用工具来提升爬虫开发的效率。它促使开发者思考如何将爬虫逻辑与具体页面结构解耦,这有助于推动爬虫工具向更模块化、可配置化的方向发展。虽然项目的具体实现细节和适用场景需要进一步探究,但其提出的“通用解决方案”概念,为网页数据抓取领域的技术实践提供了有价值的参考方向。