Fetch MCP Server:灵活的网页内容抓取与转换工具
TechFoco 精选
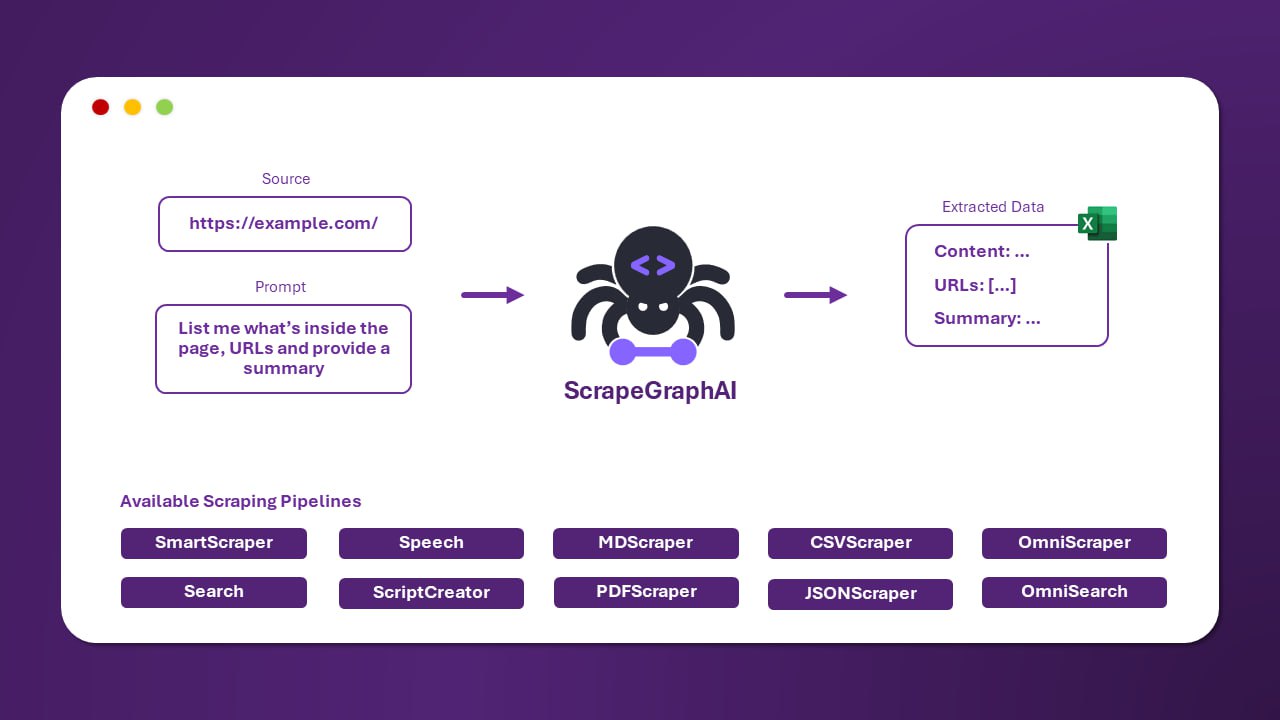
Fetch MCP Server 是一个基于 Model Context Protocol 的 HTTP 获取服务器,能够抓取网页内容并将其高效地转换为 HTML、JSON、纯文本和 Markdown 等多种格式。

在数据处理和内容聚合的工作流中,从网页获取并转换信息是一个常见需求。Fetch MCP Server 作为一个专门为此设计的工具,提供了一个标准化的协议接口,旨在简化网页内容的抓取与格式转换过程。
核心内容
Fetch MCP Server 的核心功能围绕灵活的 HTTP 内容获取与格式转换展开。它作为一个 Model Context Protocol 服务器运行,主要特性包括:
- 支持多种输出格式:能够将抓取到的网页内容转换为 HTML、JSON、纯文本和 Markdown 等格式,满足不同下游处理需求。
- 基于现代技术栈:底层使用现代的 fetch API 进行网络请求,并允许用户自定义请求头,以适应复杂的抓取场景。
- 高效的解析与转换:通过集成 JSDOM 和 TurndownService 这两个库,实现了对 HTML 文档的高效解析以及向 Markdown 等格式的精准转换。
价值与影响
该工具的价值在于为开发者提供了一个封装良好的协议化解决方案,将网页抓取、内容解析和格式转换等多个步骤整合到一个统一的接口中。这有助于降低构建数据采集或内容处理管道的复杂度,提升开发效率。其基于 MCP 的设计也使得它能够更容易地集成到支持该协议的 AI 应用或自动化工作流中,扩展了其应用场景。