Crawlee Python:现代爬虫与自动化的全栈框架
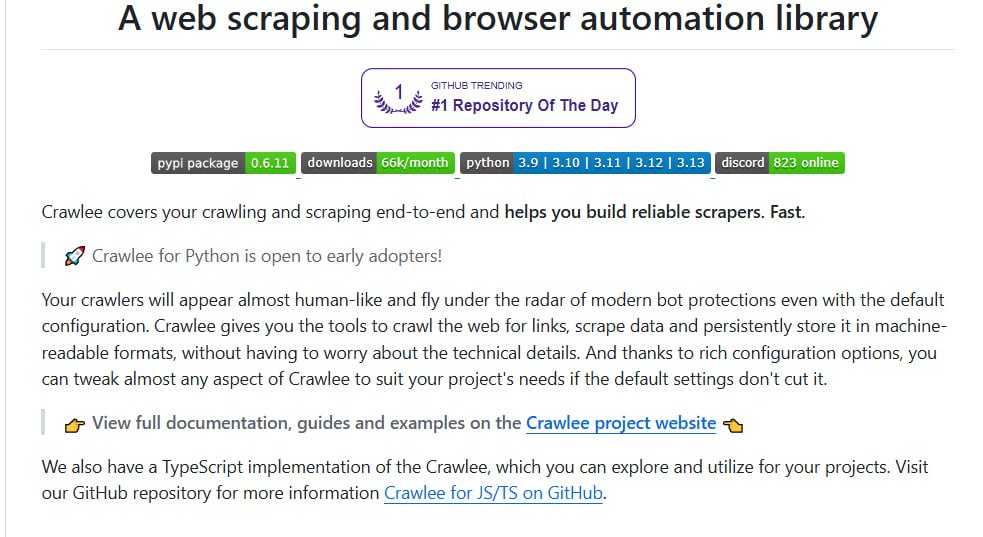
Crawlee Python 是一个全栈爬虫与自动化框架,支持 HTTP 请求和 Playwright 浏览器模式,内置反爬虫机制和异步架构,适用于高效稳定的数据抓取与网页交互。
在数据驱动的时代,高效、稳定地获取网络数据是许多应用的基础。传统的爬虫工具往往在应对复杂动态网页、反爬虫策略以及大规模并发时面临挑战。Crawlee Python 作为一个全栈解决方案,旨在为开发者提供一套统一的工具集,以应对现代爬虫与自动化任务中的各类需求。
核心内容
Crawlee Python 的核心设计围绕高效、稳定与可扩展性展开。其统一支持 HTTP 请求与 Playwright 无头浏览器模式,允许开发者在性能优先的简单抓取和需要完整渲染的复杂交互场景之间灵活选择。
框架内置了代理轮换、会话管理和自动重试等机制,这些功能有助于智能避开常见的反爬虫检测,从而提升爬取任务的整体成功率。在架构层面,它采用 asyncio 异步模型,并提供了完整的类型提示,这不仅优化了运行效率,也显著改善了开发体验。
对于任务管理,Crawlee Python 提供了灵活的请求路由与持久化队列,支持多任务并行执行与断点续爬功能,这有助于节省运维成本并保证长时间任务的可靠性。在数据输出方面,它支持存储结构化数据以及下载多种格式的文件,如 HTML、PDF、JPG、PNG 等,以满足不同场景的需求。
此外,该框架兼容 BeautifulSoup 进行页面解析,并能与 Playwright 的浏览器自动化能力深度结合,实现了从静态页面到动态内容的全方位抓取覆盖。最后,它可以轻松集成至 Apify 云平台,将本地爬虫扩展为云端自动化能力,适用于学术研究、AI 训练数据采集以及 RAG 知识库构建等更广泛的领域。
价值与影响
Crawlee Python 通过提供一套功能完备、设计现代的爬虫框架,降低了构建和维护复杂数据采集系统的门槛。其强调的方法论完善与流程稳定性,使开发者能够更专注于业务逻辑而非底层基础设施。对于需要处理多样化数据源、应对严格反爬措施或进行大规模自动化任务的企业与研究人员而言,该工具提供了一条可行的技术路径。其开源特性与详细的示例教程,也有助于社区共同推进网络数据采集技术的最佳实践。