Crawlee-Python:Python 网络爬虫与浏览器自动化库
TechFoco 精选
Crawlee-Python 是一个用于 Python 的端到端网页抓取与数据抓取解决方案,支持快速构建可靠爬虫,并具备模拟人类行为和规避现代反爬虫技术的能力。
在数据驱动的时代,高效、可靠地从互联网获取结构化信息是许多技术应用的基础。网络爬虫作为实现这一目标的关键工具,其开发过程常常面临反爬虫机制、网站结构复杂性以及维护成本高等挑战。传统的爬虫脚本往往在可扩展性、健壮性和易维护性上有所不足。

核心内容
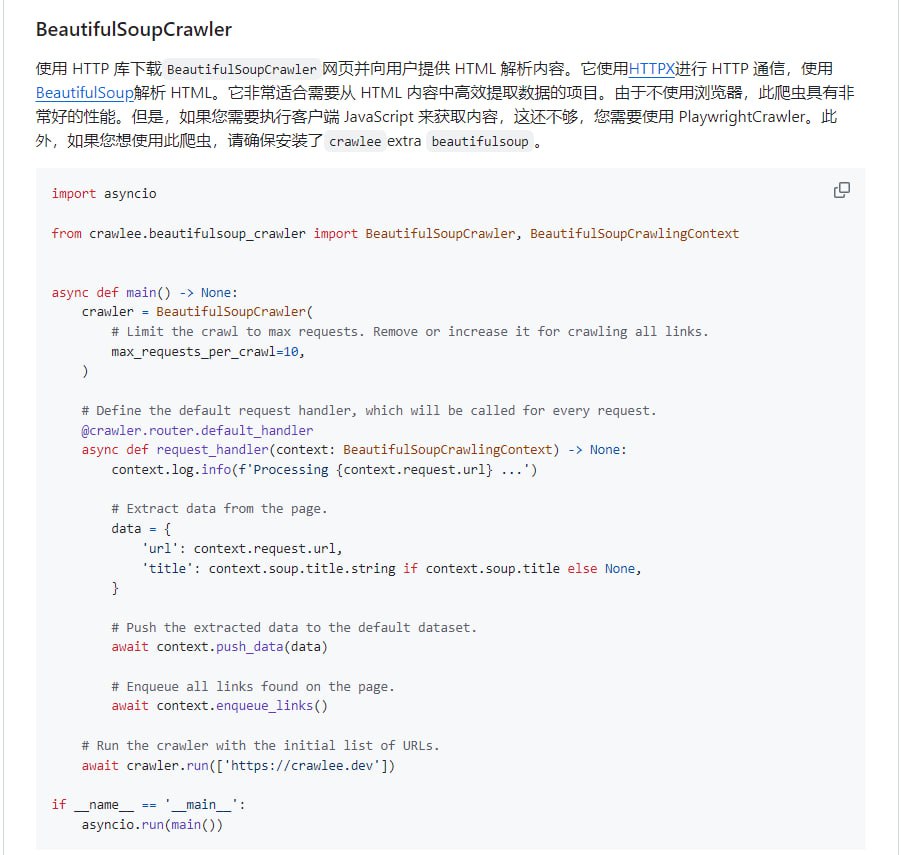
Crawlee-Python 是一个 Python 网络爬虫与浏览器自动化库,旨在提供一套端到端的网页抓取与数据抓取解决方案。它并非简单的请求库,而是一个集成了多种最佳实践的框架,支持开发者快速构建生产级别的可靠爬虫。
该库的核心能力主要体现在两个方面。其一,是内置的人类行为模拟功能,能够通过控制请求频率、鼠标移动轨迹等方式,使爬虫行为更贴近真实用户,从而降低被目标服务器识别和封锁的风险。其二,是针对现代反爬虫技术的规避能力,它整合了代理管理、请求头轮换、JavaScript 渲染处理等策略,帮助爬虫应对复杂的反爬措施。
价值与影响
对于开发者而言,Crawlee-Python 的价值在于将分散的爬虫工程实践封装成统一的、易于使用的接口。它简化了从网页请求、解析到数据存储的整个流程,降低了构建和维护稳健数据采集系统的技术门槛。该库的出现,为 Python 生态下的数据采集任务提供了一个标准化、工业级的工具选择,有助于提升爬虫项目的成功率和开发效率。





