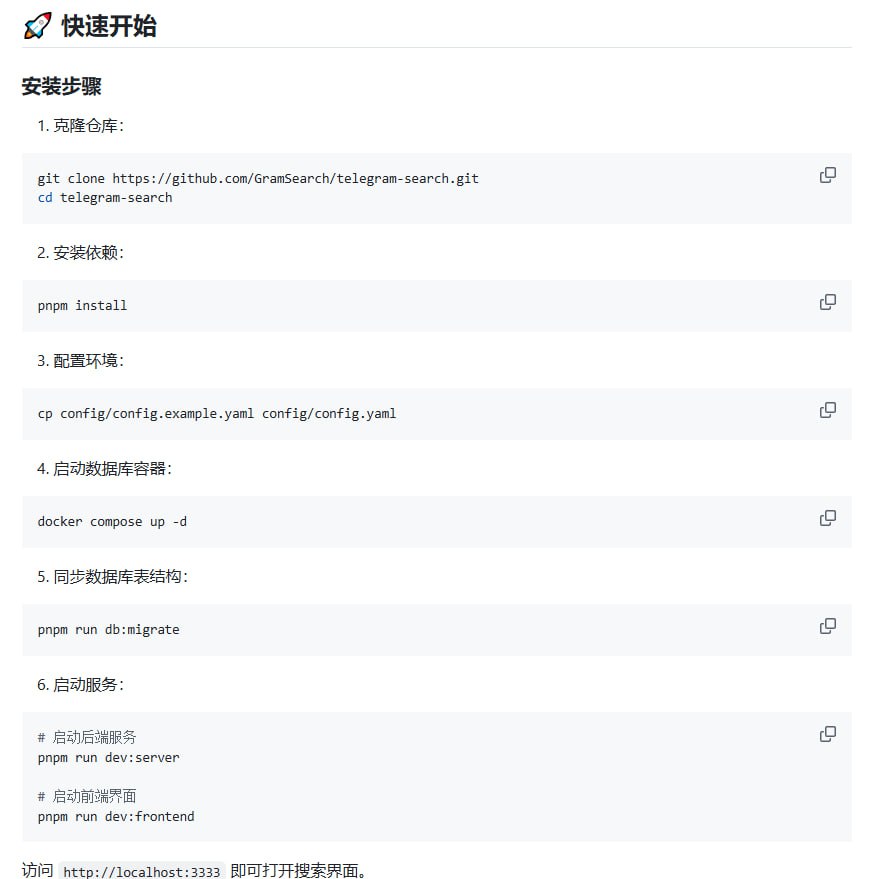
Google TurboQuant:将 KV Cache 压缩至 3 比特
Google Research 发布 TurboQuant 压缩算法,通过 PolarQuant 和 QJL 两步,将大语言模型推理时的 KV cache 内存占用压缩至 3 比特,内存减少 6 倍以上,计算速度显...
随着大语言模型(LLM)的规模持续增长,推理过程中的内存瓶颈日益凸显。一个关键制约因素是键值缓存(KV cache),它类似于模型在生成文本时实时查阅的“笔记”。随着处理上下文长度的增加,KV cache 的体积会急剧膨胀,率先耗尽内存资源,这已成为当前长文本任务面临的主要挑战。

核心内容
Google Research 最新提出的 TurboQuant 算法,旨在从根本上解决 KV cache 的内存效率问题。其核心创新在于两步压缩流程:
- PolarQuant:将传统的直角坐标向量表示转换为极坐标形式。这一转换类似于将“向东3步、向北4步”的描述改为“沿37度角走5步”,从而消除了传统量化方法中为校准边界所必需的冗余存储开销。
- QJL:使用仅 1 比特来处理第一步压缩后残留的微小量化误差。这一步在有效消除偏差的同时,实现了零额外内存开销。
整个压缩过程没有引入新的“存储税”。测试结果表明,TurboQuant 能够将 KV cache 稳定压缩至 3 比特。这带来了显著的性能提升:内存占用减少 6 倍以上,在 NVIDIA H100 GPU 上计算注意力分数的速度最高提升 8 倍。在问答、代码生成和长文本摘要等标准基准测试中,模型精度几乎没有可见损失。
与许多依赖经验调优的方法不同,TurboQuant 在数学上是可证明的,其运行效率接近理论下界,并且无需针对特定数据集进行参数调整,展现了良好的通用性。
价值与影响
TurboQuant 的价值不仅限于优化大语言模型的推理。它对依赖高维向量相似性搜索的应用,如现代语义搜索引擎,也具有直接影响。这类系统通常需要存储和检索数十亿量级的向量,压缩效率的每一点提升都能直接转化为成本降低和响应速度的加快。
该技术的出现,通过将压缩推向极致,重新定义了 AI 系统在内存受限场景下的效率边界,为未来更大规模、更复杂模型的部署与应用提供了新的可能性。