LangDiff:专为 LLM 流式结构化输出设计的 Python 库
LangDiff 是一个 Python 库,旨在解决 LLM 流式结构化输出时前端同步的难题。它通过 Pydantic 风格模型定义、JSON Patch 差异生成和变更追踪,实现高效、类型安全的数据传输与状态同步。
在构建基于大型语言模型(LLM)的应用时,流式输出是提升用户体验的关键技术。然而,当输出需要是结构化的数据(如 JSON 对象)时,如何在前端实时、高效且安全地同步这些逐步生成的数据,成为一个显著的开发挑战。传统方法往往需要反复发送完整对象,导致网络开销大、状态管理复杂。
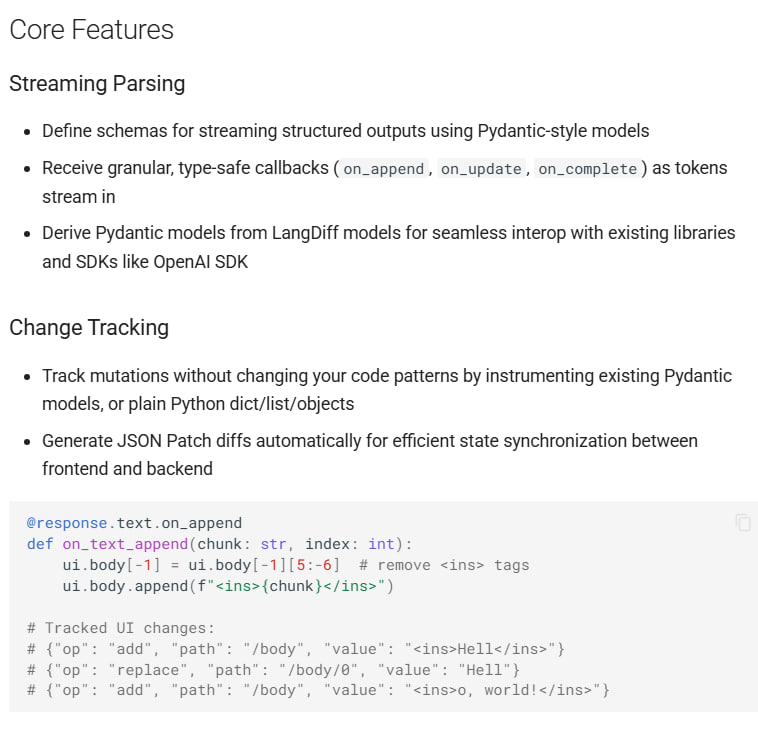
核心内容
LangDiff 是一个专为解决此问题而设计的 Python 库。其核心机制围绕结构化流式数据的生成与同步展开。
首先,它允许开发者使用熟悉的 Pydantic 风格模型来定义期望的输出数据结构。在 LLM 逐 token 生成内容的过程中,LangDiff 会进行智能解析,并触发细粒度的、类型安全的事件回调,例如 on_append、on_update 和 on_complete。这为开发者提供了对数据生成过程的精确控制。
其次,库的核心优势在于其自动化的差异处理能力。它能够实时生成符合 RFC 6902 标准的 JSON Patch,仅将对象的变化部分(差异)发送给前端,而非整个对象。这显著减少了网络传输的数据量,并简化了前端的状态更新逻辑。
此外,LangDiff 内置了变更追踪功能,可以无侵入式地监控 Pydantic 模型对象的状态变化,轻松捕获所有修改,从而确保前端界面与后端数据模型始终保持一致。
价值与影响
LangDiff 通过上述设计,有效地解耦了前端与后端架构。后端开发者可以灵活地调整提示词和输出数据结构,而无需过度担心对前端兼容性的破坏或实现细节的泄露。这提升了 AI 应用在长期演进过程中的可维护性。
该库适用于多种需要流式生成结构化内容的场景,例如多章节文章的分段输出、复杂 JSON 配置数据的逐步加载等,能够极大改善最终用户的交互体验。作为一款采用 Apache-2.0 许可的开源项目,LangDiff 提供了完整的示例和演示,便于开发者快速集成到现有项目中,推动 AI 应用前端向更响应式、更高效的方向发展。




