LangChain LLM Graph Transformer:高效构建知识图谱
本文介绍了 LangChain LLM Graph Transformer 工具,它能将非结构化文本高效转化为结构化知识图谱,支持双模式提取、灵活定义 Schema、兼容 Neo4j 数据库,并采用异步处理以提升大...
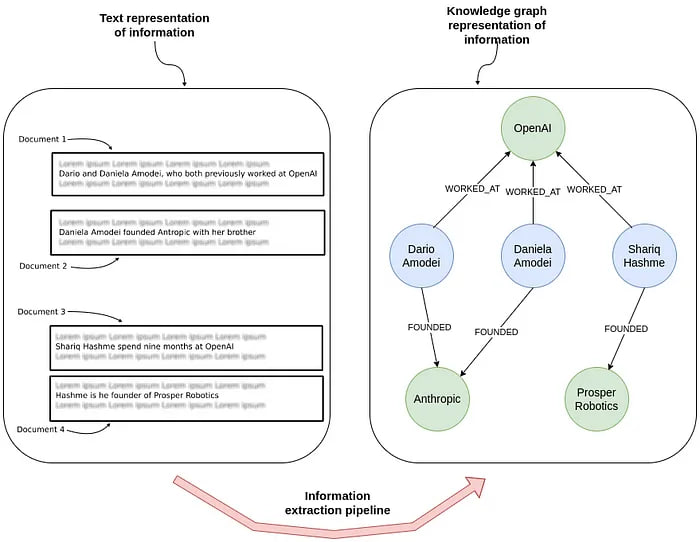
在信息爆炸的时代,如何从海量非结构化文本中高效提取、组织并利用知识,是推动智能应用发展的关键挑战。传统方法在处理复杂实体关系和多跳推理时存在瓶颈。知识图谱作为一种结构化的知识表示方式,为这一难题提供了解决方案。近期,基于大语言模型(LLM)的自动化构建工具受到关注,其中 LangChain LLM Graph Transformer 是一个值得关注的核心组件。
核心内容
LangChain LLM Graph Transformer 的核心功能是将非结构化文本高效转化为结构化的知识图谱。它通过提取文本中的实体、关系及其属性,构建出节点与边清晰定义的图结构,从而支持复杂的多跳推理和检索增强生成(RAG)等应用。
该工具在技术实现上提供了双模式支持以确保广泛适用性。默认的工具模式利用 LLM 的结构化输出或函数调用能力,精准提取节点、关系和属性。备选的提示模式则通过 few-shot 提示来兼容不支持工具调用的模型。
用户能够灵活定义知识图谱的 Schema,包括节点类别、关系类型以及属性,这种细粒度的设定显著提升了提取结果的一致性和准确性,并减少了不同运行间的输出波动。同时,工具提供的严格模式(strict_mode)可以自动过滤不符合预定义 Schema 的冗余信息,保证了生成图谱的清晰与规范。
在数据存储与集成方面,该工具兼容 Neo4j 图数据库,支持云端 Neo4j Aura 服务或本地部署,便于将提取的图谱数据便捷导入。它还可以关联源文档,实现结构化图谱检索与非结构化原文检索的融合。
为应对大规模处理需求,工具采用了异步处理机制,支持对多个文档进行并行提取,从而大幅提升构建效率。需要注意的是,目前属性抽取功能仅限于工具模式,且所有属性均以字符串形式存储,其定义在全局范围内统一。未来有望实现更细粒度的属性定制。
价值与影响
通过 LangChain LLM Graph Transformer 将文本转化为结构化的知识图谱,极大增强了数据的可查询性与推理能力。它突破了传统关键词匹配或向量检索在理解复杂语义关系上的局限,为构建更智能、更精准的知识驱动型应用(如智能问答、深度分析系统)提供了坚实的数据基础。该工具的出现,标志着利用 LLM 自动化构建高质量知识图谱的技术路径正趋于成熟,有助于降低知识工程的门槛并推动相关应用迈向新高度。



