别让 AI 废掉你的编程内功
LLM 降低了开发门槛,但也带来了技能萎缩的风险。文章指出,通过刻意练习保持技术深度,并成为具备跨领域知识的 T 型人才,才能在 AI 驱动的代码生产时代建立差异化优势。
TechFoco

共 32 篇文章,按时间倒序展示。
LLM 降低了开发门槛,但也带来了技能萎缩的风险。文章指出,通过刻意练习保持技术深度,并成为具备跨领域知识的 T 型人才,才能在 AI 驱动的代码生产时代建立差异化优势。
paper2code 是一款 AI Agent 插件,旨在解决论文复现中因细节模糊导致的效率低下问题。它通过引用锚定和模糊性审计,将论文转化为可追溯、结构完整的代码项目,并明确标注未指定内容。

本文探讨了无限上下文与检索增强生成(RAG)的关系,指出RAG的核心价值在于解决知识的时效性、可追溯性和成本控制问题,而非单纯扩展上下文。长上下文模型存在信息关注度衰减问题,两者未来更可能协作而非替代。
Sirchmunk 是一种创新的“无向量数据库”搜索方案,直接在原始文件中即时搜索,利用蒙特卡洛采样和 LLM 生成结构化知识,支持实时自我进化。

Hermes Agent 是一个完全开源的 AI 智能代理,可部署于本地服务器,集成多聊天平台,具备持久记忆、任务自动化与安全沙箱执行能力,支持灵活切换多种大语言模型。

中国研究者发现,LLM 中不到 0.1% 的特定神经元(H-Neurons)可预测幻觉,其根源在于预训练和微调的激励机制鼓励模型“过度顺从”。

Forbes数据显示,大厂新员工中应届生占比已从疫情前的50%以上骤降至7%。本文探讨了AI工具提升资深开发者效率、经济周期调整以及由此引发的行业“经验陷阱”问题。

Stephen Wolfram 宣布将 Wolfram Language 作为 LLM 的基础工具,提出计算增强生成概念,旨在为语言模型提供实时精确计算能力。然而,其闭源生态、训练数据缺失以及与成熟 Python...

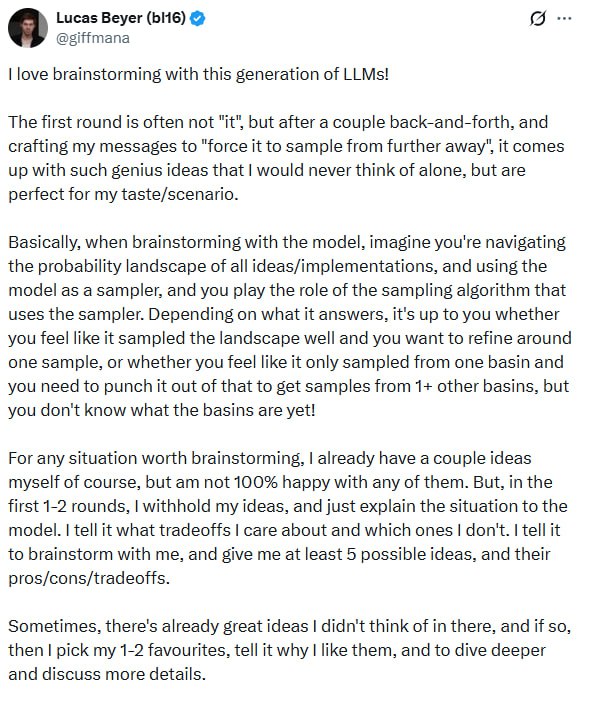
本文介绍了 Lucas Beyer 提出的人与 LLM 协作进行头脑风暴的方法论,核心是将人类角色从提问者转变为采样算法的引导者,通过延迟同步、跨越概率盆地等原则,结合人类直觉与 AI 的穷举能力,实现突现式创新。
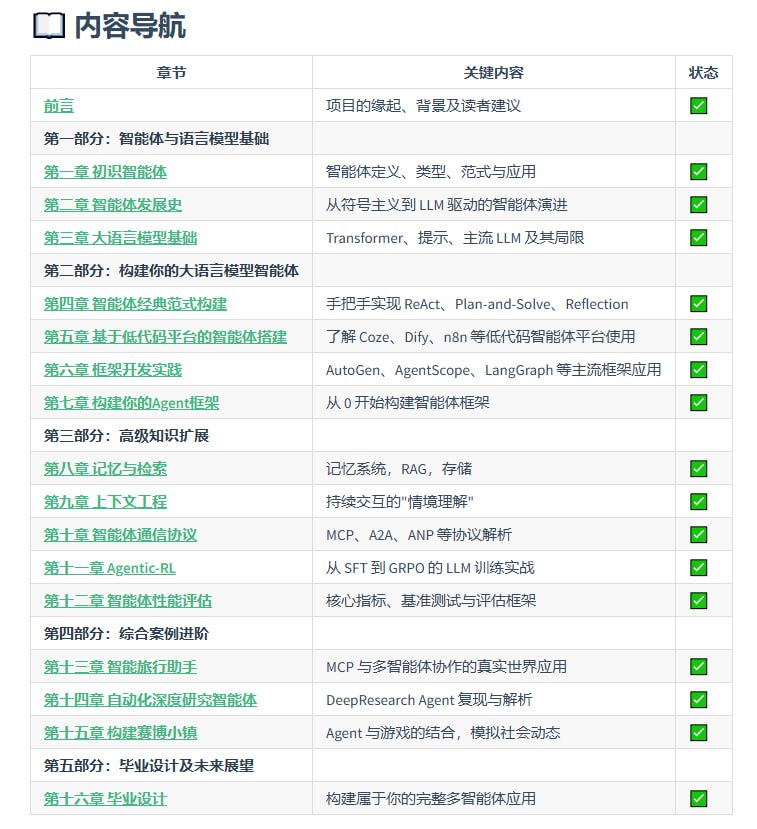
Datawhale 社区的开源教程《从零开始构建智能体》系统性地介绍了 AI 原生智能体的核心原理与实践路径,旨在帮助开发者从理论到实战,掌握构建多智能体系统的完整技能。
本文系统梳理了构建 Vector RAG 系统的九个核心步骤,包括数据采集、文本切分、向量嵌入、存储检索、流程编排、模型生成、监控与优化,并列举了各环节的常用工具与技术选型。

《开源大模型食用指南》是一个开源项目,旨在降低学习门槛,提供基于 Linux 环境的全流程教程,涵盖环境配置、主流模型部署、全量与 LoRA 微调及多模态应用。

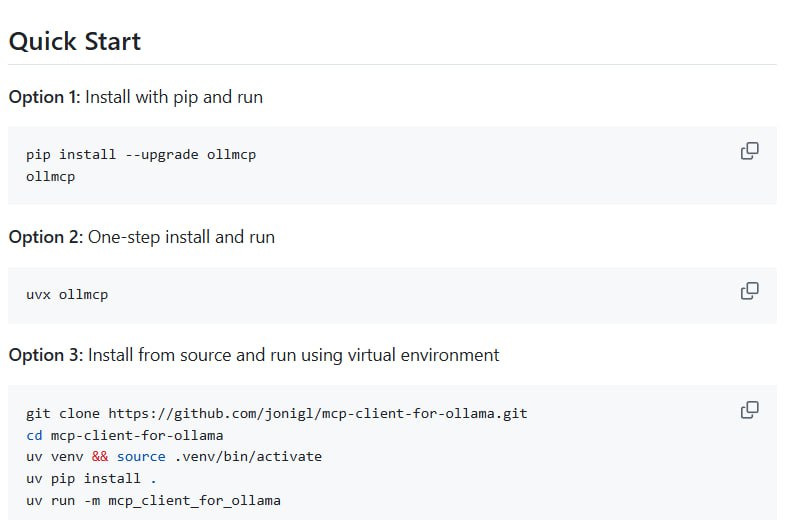
MCP Client for Ollama 是一款专为本地大语言模型开发者设计的命令行工具,它通过连接多台 MCP 服务器,简化了工具调用与工作流自动化的流程,并提供了现代化的交互界面与安全控制机制。
谷歌高级总监发布了一份 171 页的 LLM 白皮书,系统性地介绍了从 Transformer 基础到前沿模型架构、推理对齐及代码实现等核心内容。

本文系统介绍了大语言模型文本生成中的核心采样技术,涵盖多种采样方法、词元化器设计及其交互影响,旨在阐明如何通过合理组合采样策略来优化生成文本的质量。
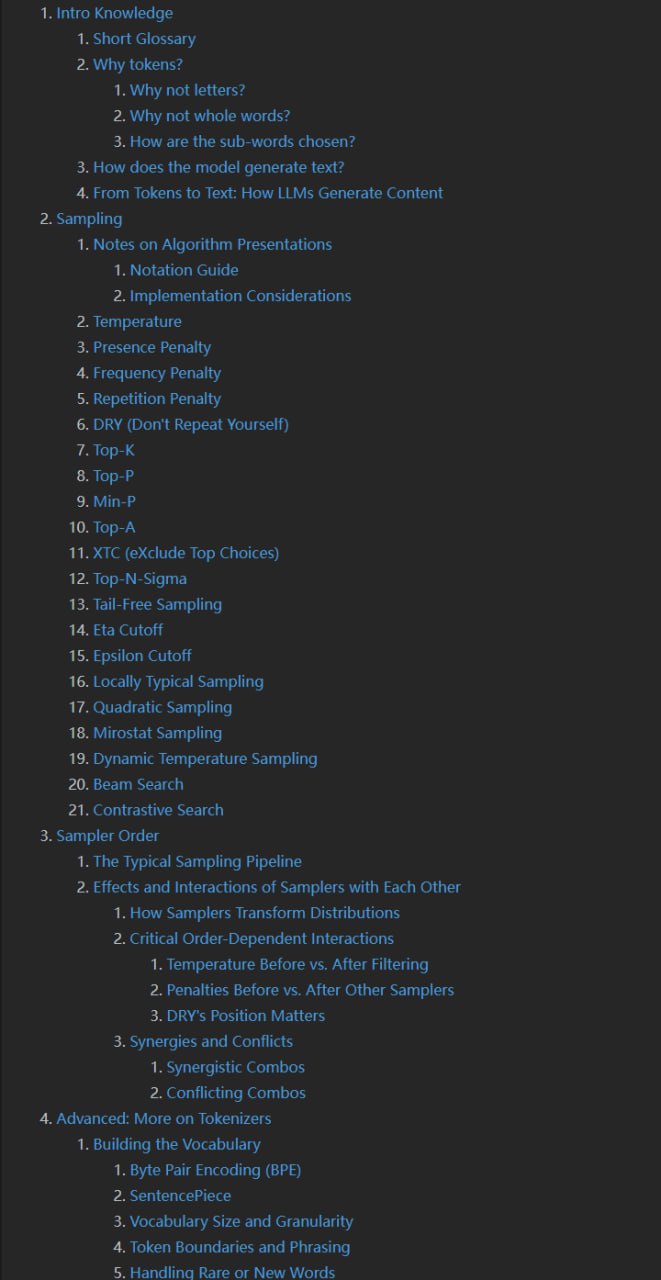
LangDiff 是一个 Python 库,旨在解决 LLM 流式结构化输出时前端同步的难题。它通过 Pydantic 风格模型定义、JSON Patch 差异生成和变更追踪,实现高效、类型安全的数据传输与状态同步。
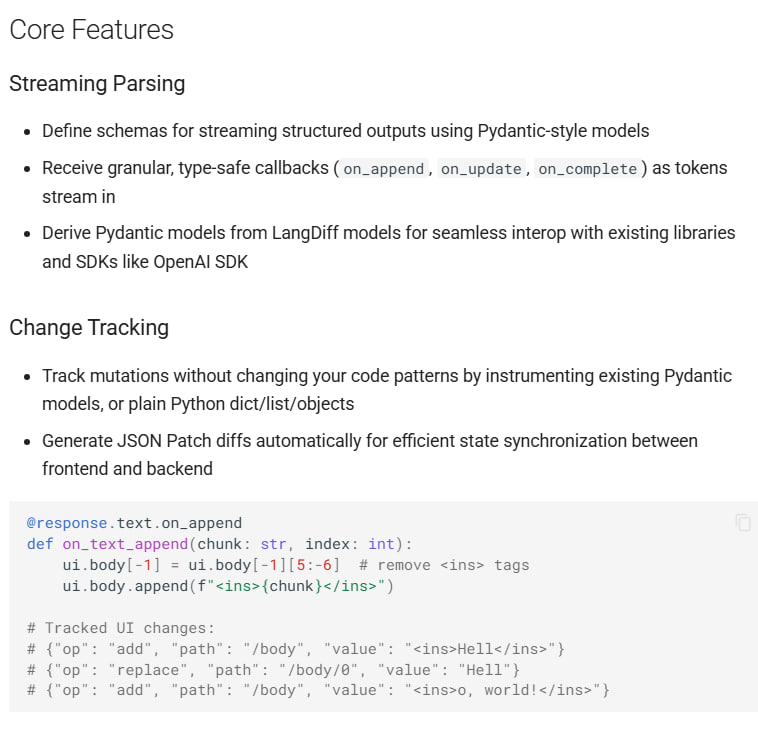
本文借鉴“汉堡”的类比,系统阐述了构建生成式 AI 应用所需的基础设施、模型、数据集成、逻辑与前端五层核心架构,并探讨了可观测性、安全校验等关键非功能需求。
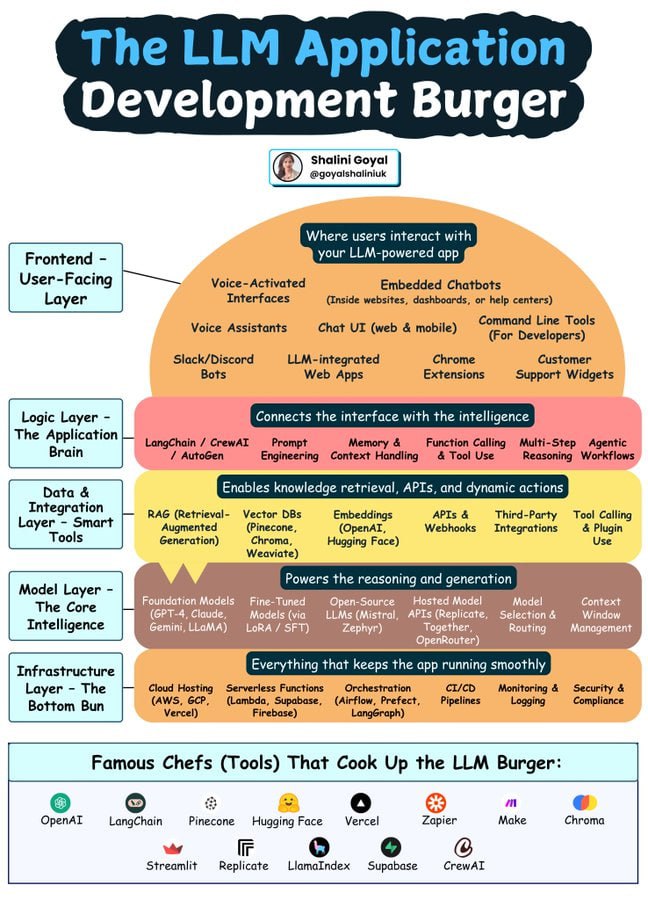
本文介绍了 LangChain LLM Graph Transformer 工具,它能将非结构化文本高效转化为结构化知识图谱,支持双模式提取、灵活定义 Schema、兼容 Neo4j 数据库,并采用异步处理以提升大...
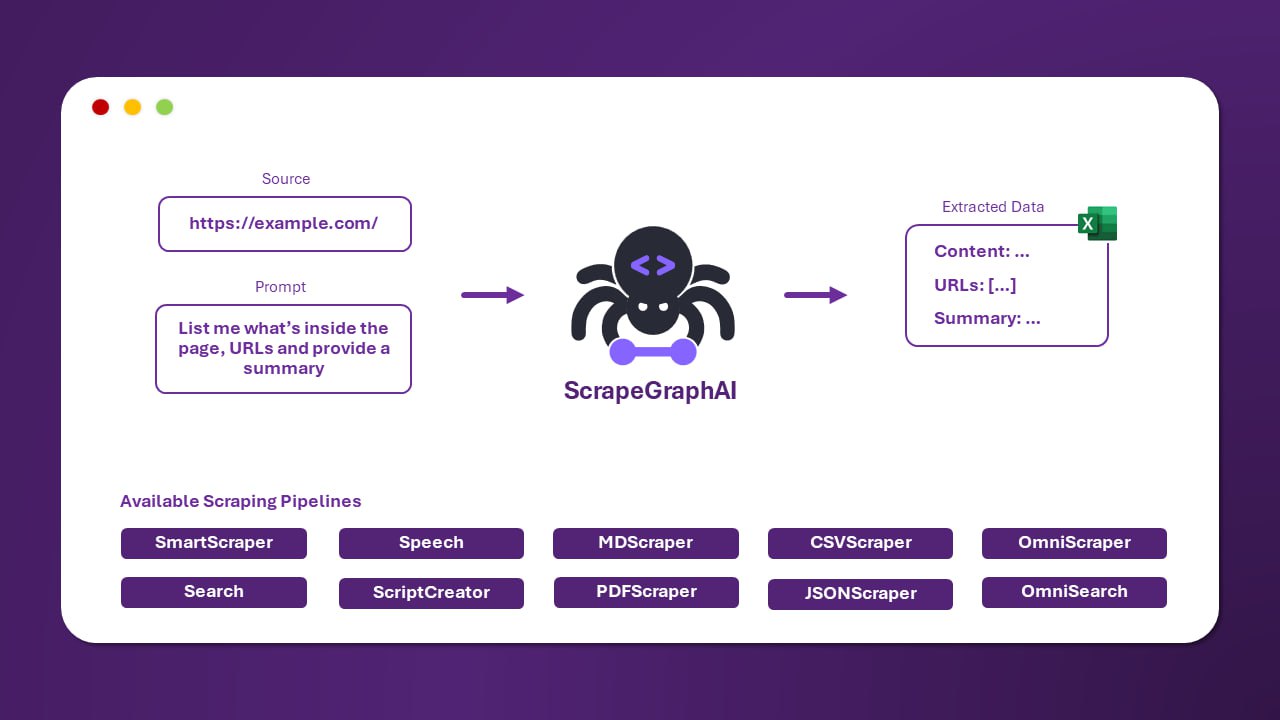
ScrapeGraphAI 是一个结合大型语言模型和图结构的 Python 爬虫库,支持多种数据源和爬取模式,旨在实现高效、智能的数据提取。
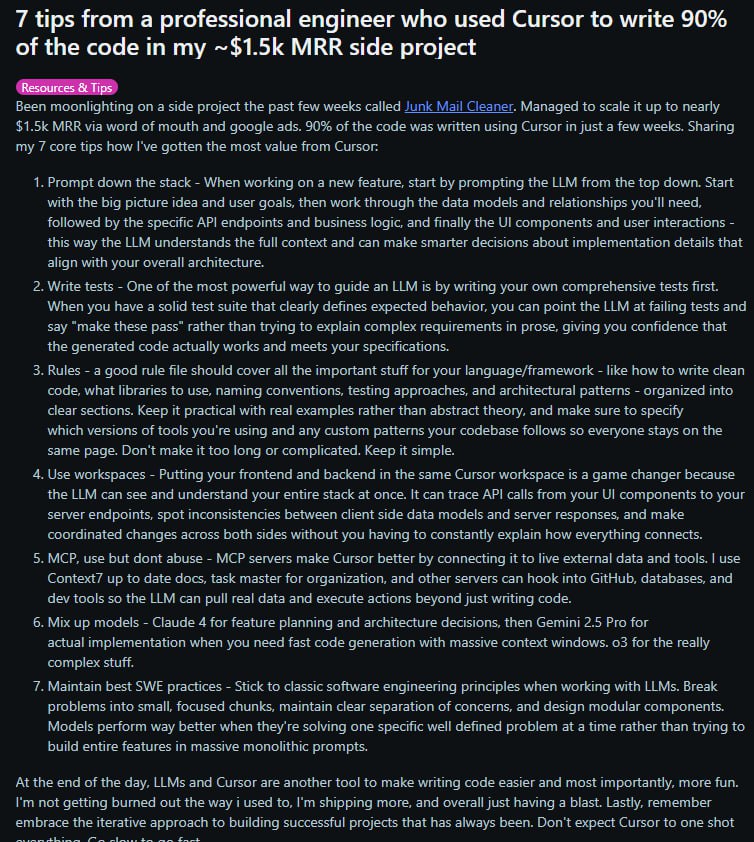
一位专业工程师分享了使用 Cursor AI 在几周内完成副业项目 90% 代码的核心技巧,包括自顶向下提示、编写测试、使用规则文件等方法,旨在提升开发效率与代码质量。