WaterCrawl:强大的网页爬取与数据提取应用
TechFoco 精选
WaterCrawl 是一款网页爬取与数据提取应用,提供深度、速度和内容定制的高级爬虫功能,支持多语言搜索,并集成了 Python、Node.js、Go 等多语言客户端 SDK。
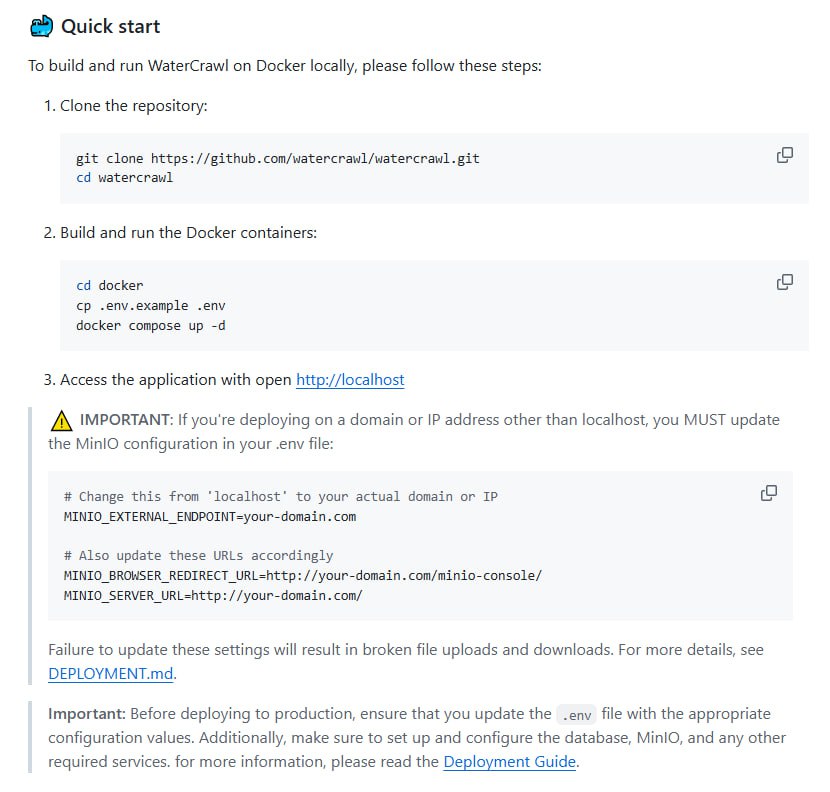
在数据驱动的时代,高效、准确地从互联网获取信息是许多应用的基础。网页爬取与数据提取技术因此成为关键工具。WaterCrawl 作为一款专注于此领域的应用,旨在为开发者提供一套强大的解决方案。
核心内容
WaterCrawl 的核心能力体现在其高级爬虫功能上。它支持对爬取深度、速度以及目标内容进行高度定制,使开发者能够根据具体需求灵活调整采集策略。
该应用还具备多语言搜索能力,可以针对不同国家和地区进行内容采集,这对于需要处理国际化内容的项目尤为重要。
为了便于集成,WaterCrawl 提供了多语言客户端 SDK,包括 Python、Node.js 和 Go 版本。这些 SDK 允许开发者在其熟悉的开发环境中无缝对接 WaterCrawl 的服务。
价值与影响
WaterCrawl 通过提供可定制、多语言支持且易于集成的工具,降低了网页数据采集的技术门槛和开发成本。其多语言 SDK 的设计,使得不同技术栈的团队都能高效地利用其能力,从而加速数据获取流程,为数据分析、市场研究、内容聚合等应用场景提供可靠的数据源支持。





