Dedoc:自动解析与统一文档格式的开源库
TechFoco 精选
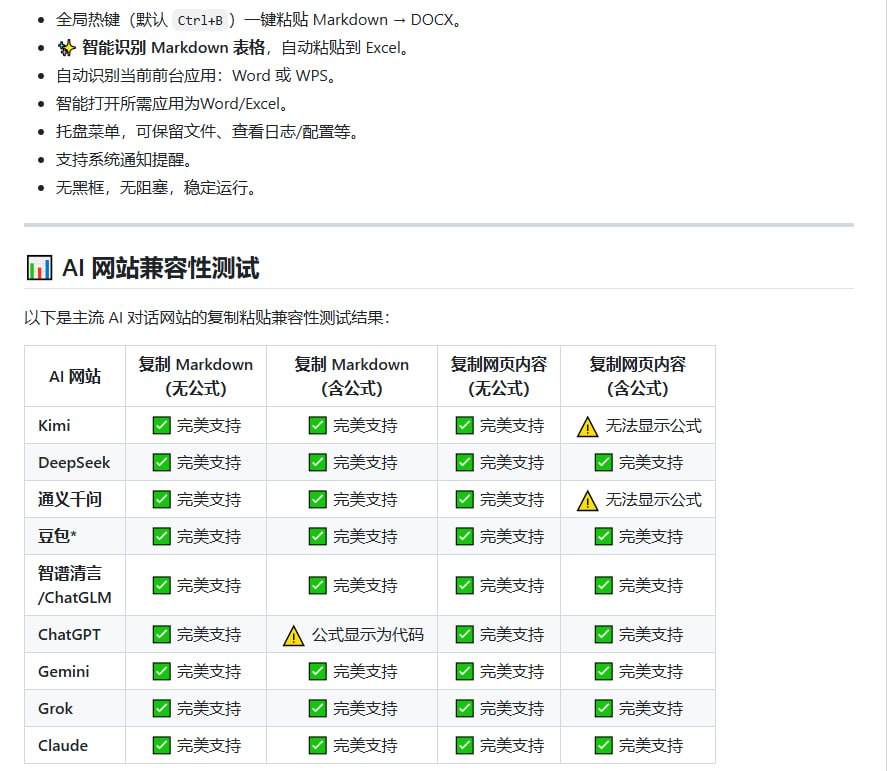
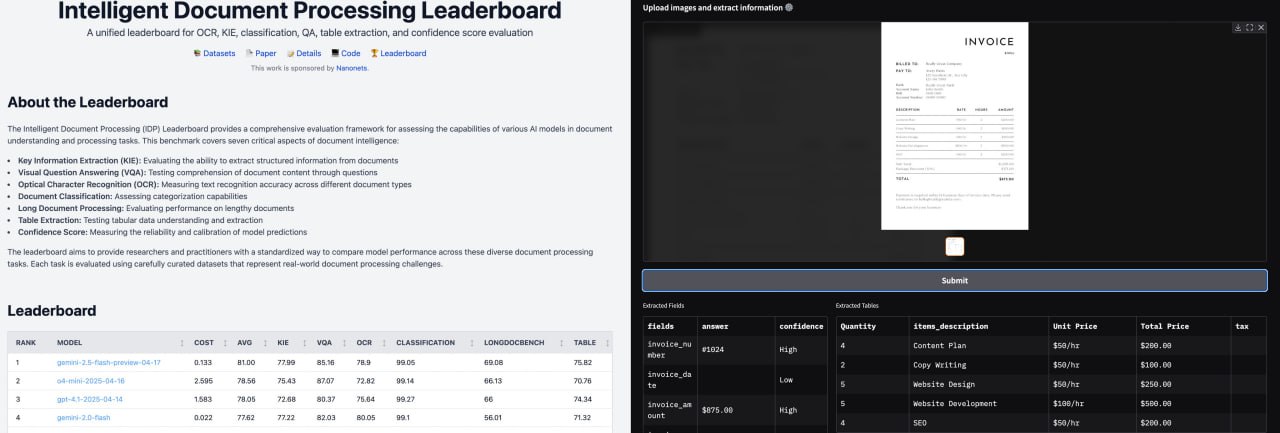
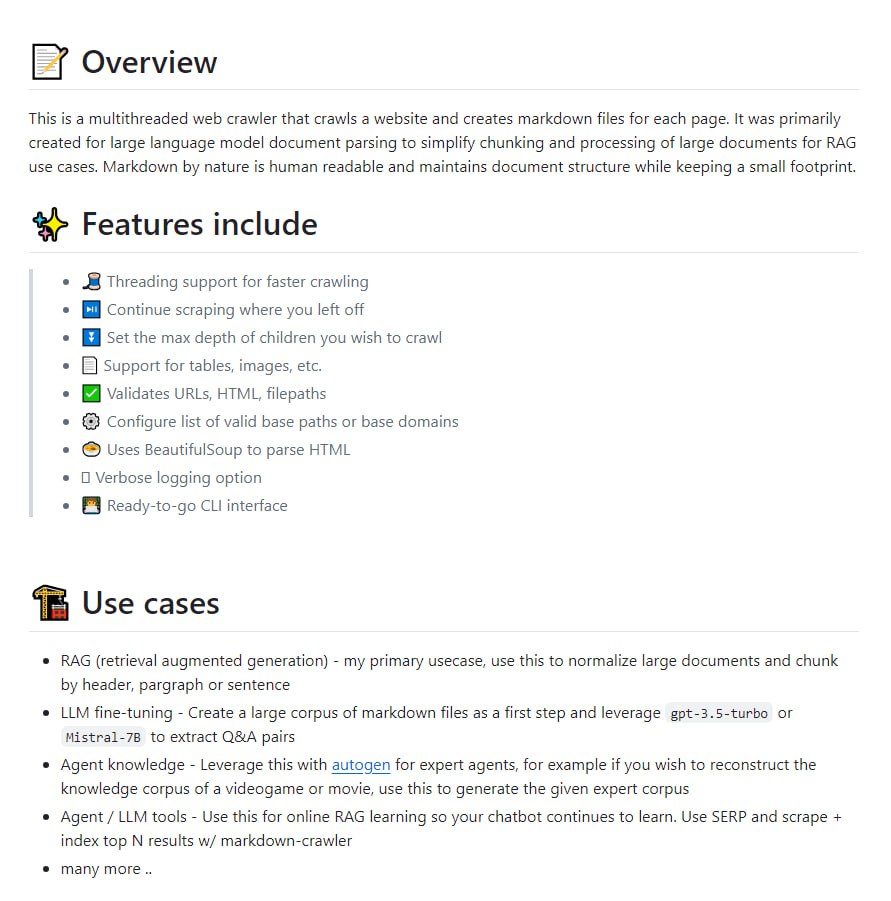
Dedoc 是一个开源库,能够自动解析 PDF、DOCX、HTML 及扫描文档等多种格式,提取文档的逻辑结构与表格,并通过 REST API 提供便捷的系统集成能力。
在数字化工作流中,处理来自不同来源、格式各异的文档是一项常见且繁琐的任务。手动提取文档内容、识别结构不仅效率低下,也容易出错。因此,能够自动解析多种文档格式并提取结构化信息的工具,对于提升信息处理自动化水平具有重要意义。
核心内容
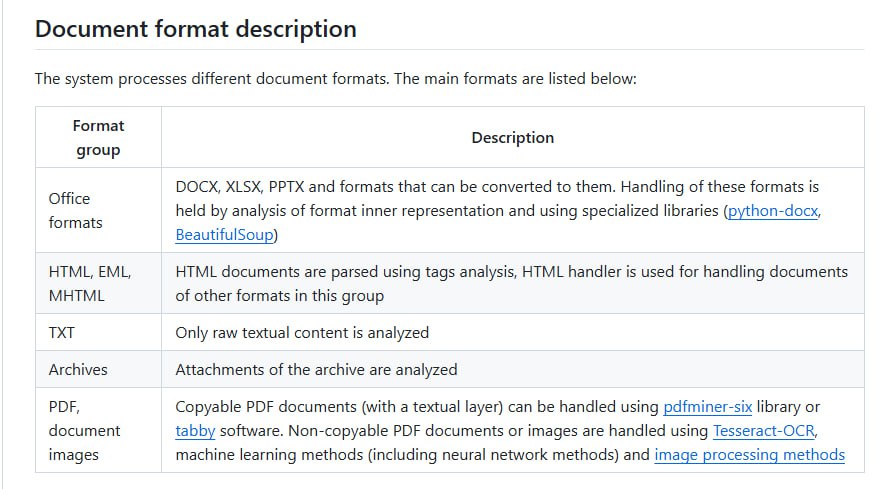
Dedoc 是一个旨在解决上述问题的开源库。其核心功能是自动解析文档并将其内容转换为统一的格式。该库支持处理多种常见的文档格式,包括 PDF、DOCX、HTML 以及扫描得到的图像文档。
在解析过程中,Dedoc 能够自动识别并提取文档的逻辑结构,例如章节标题、段落层级关系,同时也能准确地提取文档中嵌入的表格数据。为了便于开发者使用和集成,Dedoc 提供了 REST API 接口,允许将其功能轻松嵌入到现有的应用程序或系统架构中。
价值与影响
Dedoc 的出现为需要处理多格式文档的自动化系统提供了一个可行的技术方案。通过将异构文档内容转化为统一的结构化数据,它有助于简化后续的数据分析、内容管理或知识库构建流程。其开源特性和 API 优先的设计,降低了技术集成门槛,使得团队可以更专注于业务逻辑而非底层文档处理细节,从而提升开发效率与系统处理能力。