大模型数据增强文献资源综述
TechFoco 精选
本文介绍了一个专注于大语言模型数据增强技术的GitHub资源库,该库系统性地整理了相关文献与综述,为研究人员提供了集中的参考资料。
随着大语言模型在自然语言处理领域的广泛应用,如何高效提升其训练数据的质量和多样性,即数据增强技术,已成为一个关键研究方向。数据增强旨在通过现有数据生成新的、多样化的训练样本,以提升模型的泛化能力和鲁棒性。然而,相关研究分散,缺乏系统性的整理。
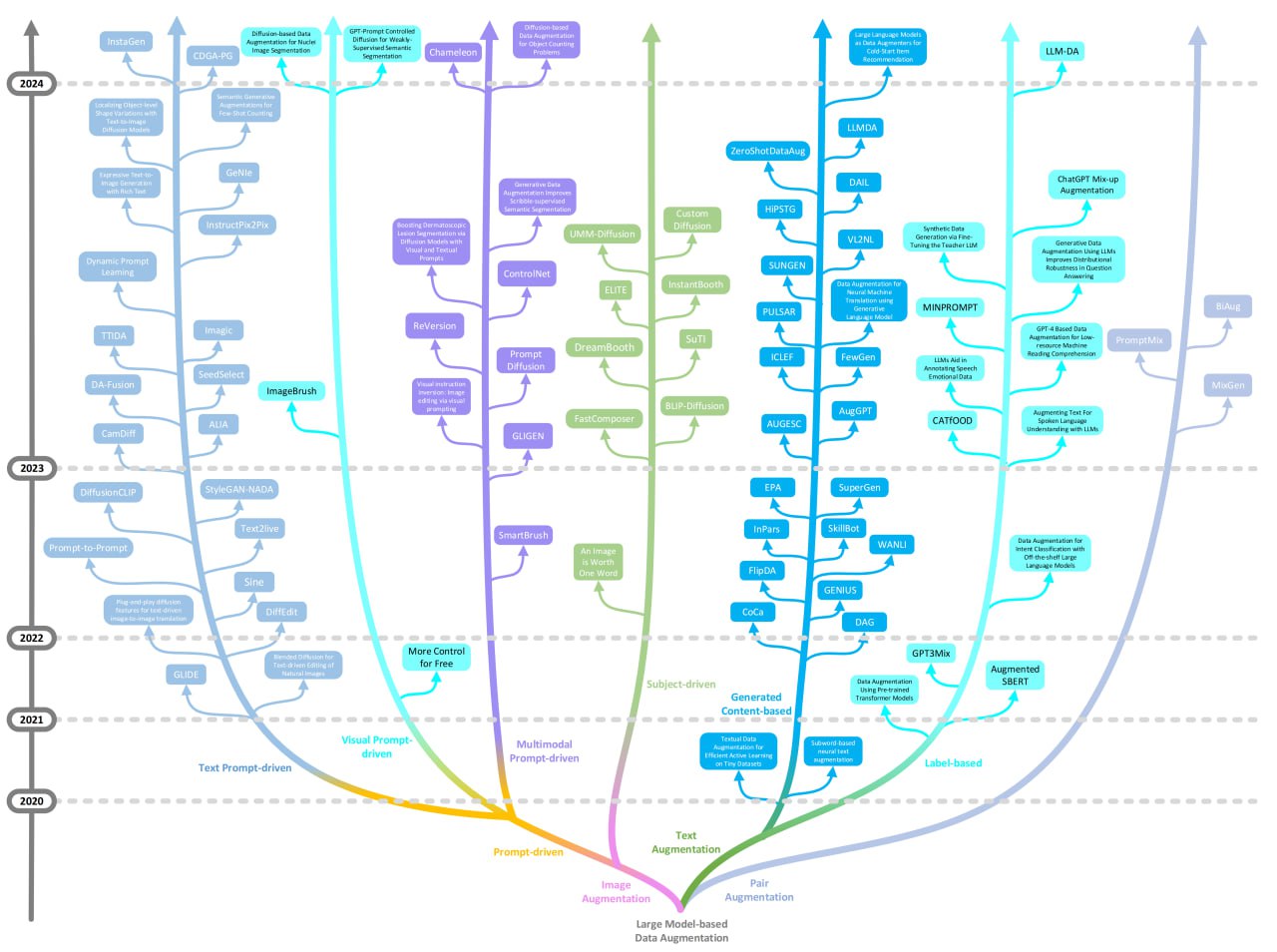
核心内容
近期,一个名为“大模型数据增强相关文献资源列表”的GitHub仓库被创建,旨在集中梳理该领域的学术资源。该资源库由MLGroup-JLU维护,其主要内容可能包括对大语言模型数据增强方法的文献列表、技术调查或综述。这为研究人员快速了解领域现状、追踪最新进展提供了一个结构化的入口。
价值与影响
该资源库的建立具有积极意义。它有助于降低研究者的信息搜集成本,促进知识的系统化整理与共享。通过汇集相关文献,该资源能够帮助社区更清晰地把握大模型数据增强技术的发展脉络、主流方法及潜在挑战,从而推动该技术方向的深入探索与应用实践。




