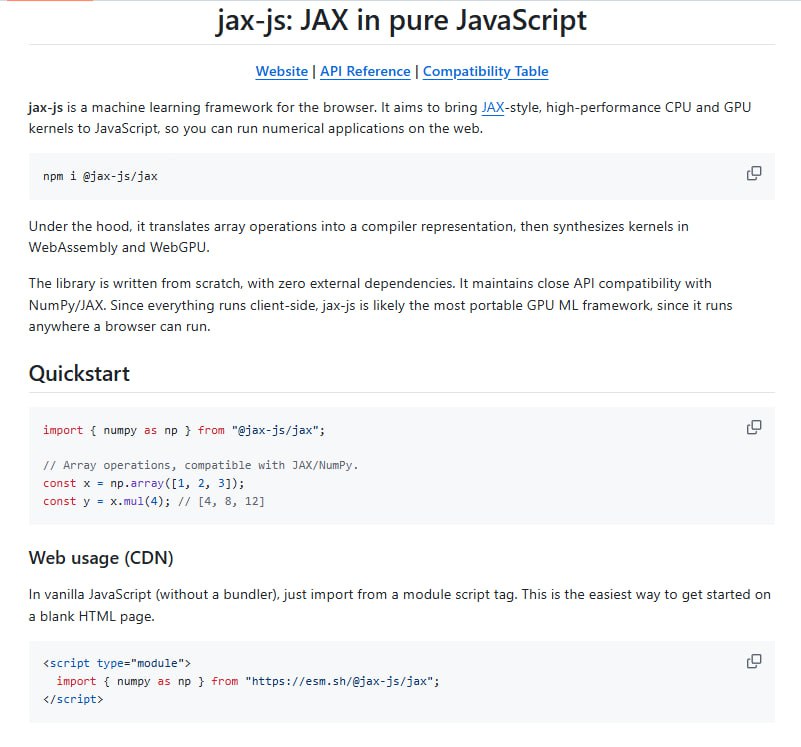
Qwen 3.5 0.8B 模型在浏览器本地运行
一个 0.8B 参数的 Qwen 多模态模型现可在浏览器中完全本地运行,无需服务器。这标志着 AI 能力正从云端 API 服务转变为前端本地组件,为注重隐私、低延迟的应用场景提供了新可能。

传统的 AI 应用开发通常遵循前后端分离的模式:前端负责用户交互界面,而核心的 AI 模型推理则部署在云端服务器,通过 API 进行调用。这种模式虽然稳定,但也伴随着成本、网络延迟和隐私数据外流等固有挑战。长期以来,强大的多模态 AI 能力被认为必须依赖云端算力。
核心内容
近期,一项技术演示打破了这一固有认知。开发者展示了一个网页,该页面能够下载并加载一个约 860MB 的资源包。随后,一个参数规模为 0.8B 的 Qwen 3.5 多模态模型便可在用户的浏览器中完全本地运行,直接调用本地 GPU 进行计算,整个过程无需连接任何远程服务器。
这一实践的关键在于技术栈的进步,使得原本需要在云端运行的轻量级模型得以通过 WebAssembly 等技术在浏览器环境中高效执行。它直接改变了 AI 能力的交付方式:对于许多中轻度智能任务,AI 不再是一个必须通过网络调用的远程服务,而更像是一个前端可以直接引入和使用的本地 JavaScript 库或组件。
由此带来的优势是明确的:
- 隐私数据完全保留在本地设备,无需上传至云端。
- 消除了网络请求带来的延迟,响应更为实时。
- 应用具备离线运行的能力,对网络环境没有依赖。
价值与影响
当视觉等 AI 能力能够像加载一个前端库一样便捷和本地化时,一系列新的应用场景将被激活。例如,在视频会议中实时分析与会者状态,或是在设备本地离线整理个人相册,这些对隐私和实时性要求较高的“看一眼”型应用成为可能。
这并不意味着云端大模型会被取代,而是预示着一个更清晰的任务分工正在形成。云端将继续处理极其复杂、需要海量算力的“原子弹”级任务;而大量轻量级、高频的“子弹”级任务,将越来越多地转移到用户终端设备上,在浏览器或本地应用中直接完成。这种架构变迁为前端开发领域注入了新的活力,AI 正成为前端开发者工具箱中的新武器。