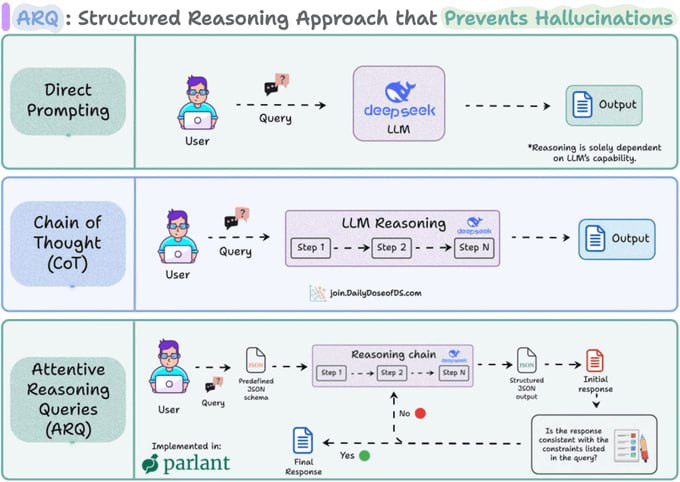
医疗AI新难题:LLM临床决策不稳定性
一项研究测试了6款医疗相关大型语言模型,发现其在临床决策中存在严重不稳定性,包括答案不一致和缺乏追问能力。研究指出,LLM更适合辅助提供选项框架,而非做出最终判断。

大型语言模型在医疗领域的应用日益广泛,尤其是在临床决策支持方面。然而,一项最新研究揭示了其在医院临床决策场景中表现出的严重不稳定性,这为医疗AI的可靠部署带来了新的挑战。
核心内容
该研究对6款医疗相关的大型语言模型进行了测试,针对4个常见的住院病例反复提问。测试结果凸显了模型在临床决策中的几个关键问题。
不同模型对同一临床问题会给出截然不同的建议。例如,在一个病例中,50%的模型建议立即重新使用血液稀释剂,而另外50%则建议延迟观察。这表明模型间缺乏共识。
同一模型在多次回答同一问题时,其答案的一致性仅约为60%。这意味着模型的回答存在反复翻转的现象,缺乏稳定性。
绝大多数模型未主动追问缺失的临床信息。这导致微小的提问措辞差异就可能引发治疗方案的分歧。此外,不同模型在风险评估上各有侧重,有的关注出血风险,有的则更担忧肾损伤或早期出院后的后果。研究最终发现,没有任何两款模型能在所有测试案例中保持答案一致。
价值与影响
研究明确指出,当前的大型语言模型更适合辅助临床医生“框架选项”,即为决策提供参考思路,而非做出最终的临床判断。临床医生在使用时应进行多模型对比、反复提问,并始终承担最终决策责任。
专家评论普遍认为,这反映了当前模型训练和架构的局限,特别是通用型LLM缺乏专门的医疗数据训练。医学决策本身带有不确定性,提升AI稳定性必须依赖更精准的训练、外部数据支持(如检索增强生成)和可审计的推理过程。
目前,医疗AI正处于探索期。它能够提出可参考的诊疗思路,但远未达到可完全信赖的成熟度。未来的发展需要更多专门训练、更严谨的验证以及人机协同的系统设计,才能真正提升临床安全与效果。