构建生产级 RAG 系统:从 BM25 到本地 LLM
本文介绍一个为期 6 周的开源实战课程,旨在系统化地指导构建一个生产级的 RAG 系统。课程从 Docker、FastAPI 等基础设施搭建开始,强调先掌握 BM25 关键词检索,再结合向量语义进行混合检索,并集成...
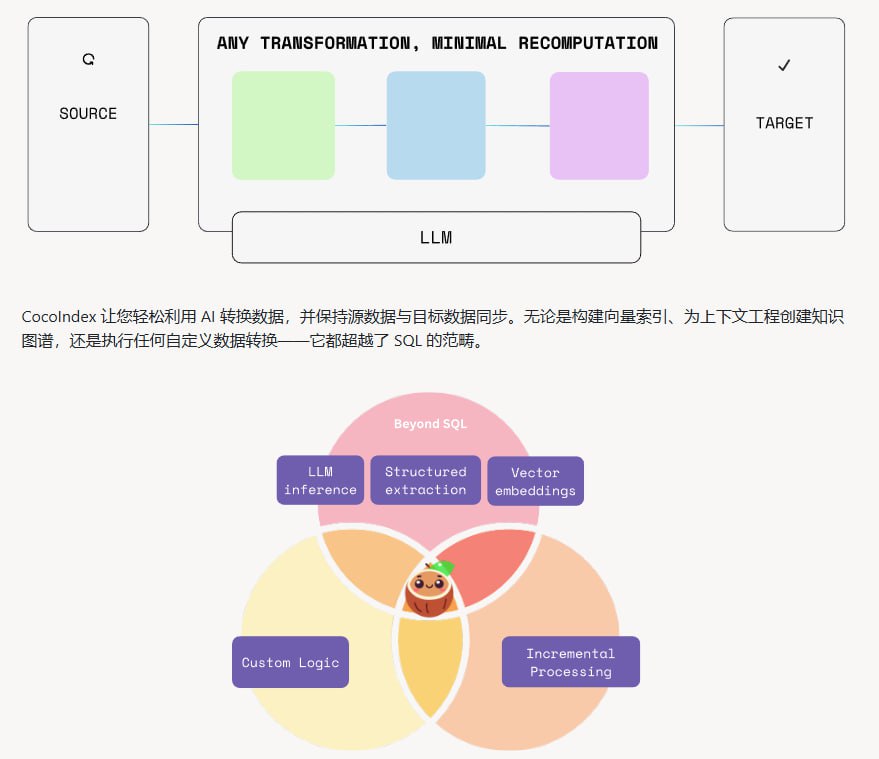
检索增强生成(RAG)系统已成为连接大型语言模型与外部知识库的关键架构。然而,构建一个稳定、高效且可投入生产环境的 RAG 系统,涉及从基础设施、检索策略到模型集成的复杂工程挑战。The Mother of AI Project 提供了一个开源、系统化的实战课程,旨在通过六周时间,手把手指导开发者构建一个完整的生产级 RAG 应用,特别聚焦于科研论文助手场景。
核心内容
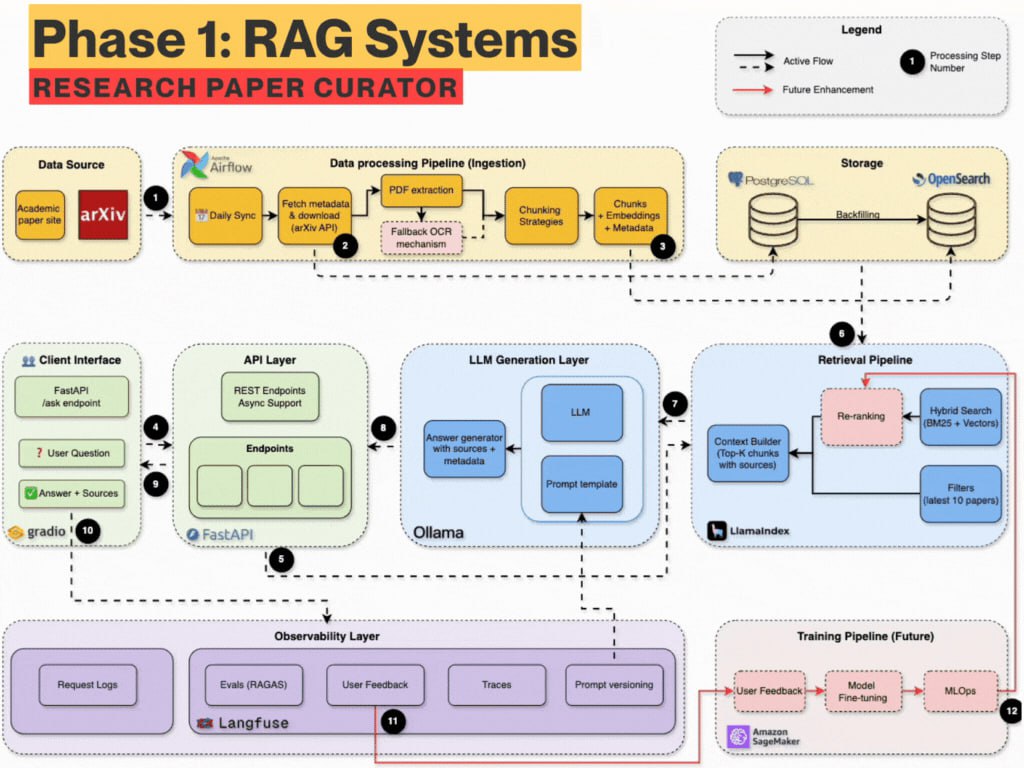
该课程设计了一条清晰的进阶路径。首先,学员需要搭建包括 Docker、FastAPI、PostgreSQL、OpenSearch 和 Apache Airflow 在内的核心基础设施,并实现 arXiv 论文的自动化抓取与解析。在检索层面,课程采用了一种反直觉但务实的设计:强调关键词搜索是根基。学员将首先深入实现并优化生产级的 BM25 算法,打好精确匹配的基础,然后再引入 Jina AI 嵌入模型进行语义搜索,最终构建结合两者优势的混合检索系统,以避免单一向量检索可能带来的召回偏差和结果不可解释问题。
在生成端,课程指导集成本地运行的 Ollama LLM,以实现数据隐私保护和流式响应。系统前端采用极简的 Gradio UI 进行交互。为了提升生产可用性,课程涵盖了多项工程化实践:利用 Langfuse 进行端到端的请求跟踪与监控;通过 Redis 缓存检索结果,据称可实现 150 到 400 倍的响应加速并显著节约成本;使用统一的 .env 文件进行配置管理,并设计异常优雅降级机制,确保系统稳定可靠。整个项目支持 Python 3.12+ 并使用 Docker Compose 一键部署。
价值与影响
该课程的价值在于其全面、实战导向且开源免费的特性。它不仅仅讲解概念,还提供了配套的 Jupyter 笔记本和详尽博客,覆盖了从智能文档切片、语义检索到生产监控的完整闭环。通过将 BM25 这类传统检索技术与现代向量搜索、本地 LLM 相结合,课程演示了如何构建一个兼顾性能、成本与控制权的 AI 应用。该项目采用 MIT 许可,允许开发者零成本在本地搭建,并灵活接入外部 API 或进行自由扩展。对于 AI 工程师、软件开发者和数据科学家而言,它提供了一个掌握 RAG 工程核心技术的绝佳实践平台,有助于构筑未来 AI 基础设施的坚实能力。