向量数据库工作原理详解:从嵌入到 HNSW 索引
本文解析了向量数据库的核心工作流程,包括通过向量嵌入将数据转化为高维空间坐标,利用 HNSW 等索引技术解决海量向量相似性搜索的挑战,并阐述了其在语义搜索和 RAG 等场景中的基础价值。
随着人工智能应用的深入,处理非结构化数据(如文本、图像、音频)的需求日益增长。传统数据库基于精确匹配的查询方式,难以应对此类数据的语义检索需求。向量数据库应运而生,其核心在于将数据转化为机器可理解的数值形式,并进行高效的相似性搜索。理解其工作原理,是构建现代语义搜索、推荐系统及 RAG(检索增强生成)应用的基础。
核心内容
向量数据库的工作流程主要围绕两个核心环节展开:向量嵌入与索引检索。
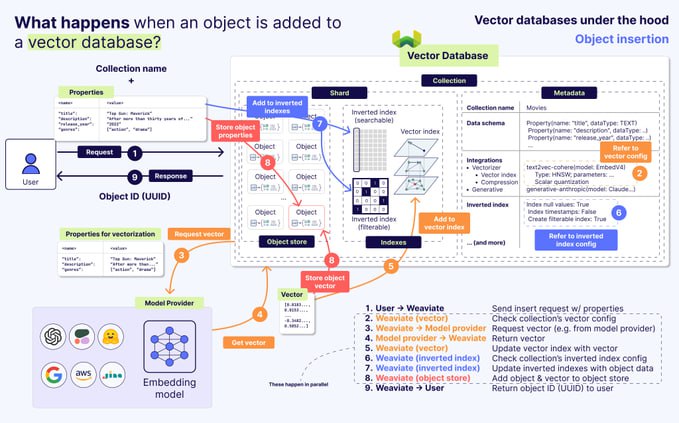
首先,任何数据(文本、图片、音频)都需要通过嵌入模型转换为向量。向量本质上是高维空间中的一组数值坐标,语义相近的内容在向量空间中的位置也彼此靠近。这一过程实现了数据的“语义数字化”,为后续的相似性比较奠定了基础。
然而,当面对百万乃至亿级别的向量时,逐一计算查询向量与所有存储向量之间的距离(即“暴力搜索”)在计算资源和时间上都是不现实的。因此,必须引入向量索引技术来组织数据,以实现快速近似最近邻搜索。HNSW(Hierarchical Navigable Small World,分层可导航小世界图)是当前广泛采用的一种高效索引方法。它通过构建一个多层图结构,将相似的向量连接起来。在查询时,算法可以从顶层开始,以“跳跃式”的方式快速导航至目标区域,从而极大提升了搜索速度,避免了全量扫描。
一个典型的搜索流程可以简述为以下几个步骤:
- 将查询输入(如一段文本)转化为查询向量。
- 使用距离度量(如余弦相似度)作为相似性判断标准。
- 利用 HNSW 等索引结构,快速定位到与查询向量最接近的一组候选向量。
- 返回最相关的结果。
在实际应用中,不同的索引方案需要在搜索速度、结果准确度(召回率)和内存等资源消耗之间进行权衡。例如,某些方案可能会牺牲微小的准确率以换取极致的响应速度。
价值与影响
以向量嵌入和高效索引为核心的技术,构成了现代许多 AI 应用的基石。它使得系统能够真正理解内容的语义,而不仅仅是关键词匹配。这项技术是驱动高级语义搜索、个性化推荐、以及当前热门的 RAG 架构的关键底层支撑。通过将复杂的近似最近邻搜索算法封装在数据库底层,开发者得以从繁琐的算法细节中解放出来,更专注于业务逻辑的创新与应用开发。向量数据库的发展,正持续推动着数据处理从“精确查找”向“智能关联”的范式转变。


