read_books.py:AI 驱动的 PDF 智能阅读与知识提取工具
TechFoco 精选
本文介绍一个基于 Python 的 read_books.py 脚本,该工具利用 AI 技术逐页解析 PDF 文档,自动提取关键知识点并生成阶段性总结,所有笔记均以 Markdown 格式保存,旨在提升阅读与知识管...
在信息过载的时代,高效阅读与知识管理成为刚需。传统的 PDF 阅读方式往往耗时费力,难以系统性地提取和回顾关键信息。针对这一痛点,开发者推出了 read_books.py 脚本,一个旨在通过 AI 技术自动化处理 PDF 文档阅读与知识提取的 Python 工具。
核心内容
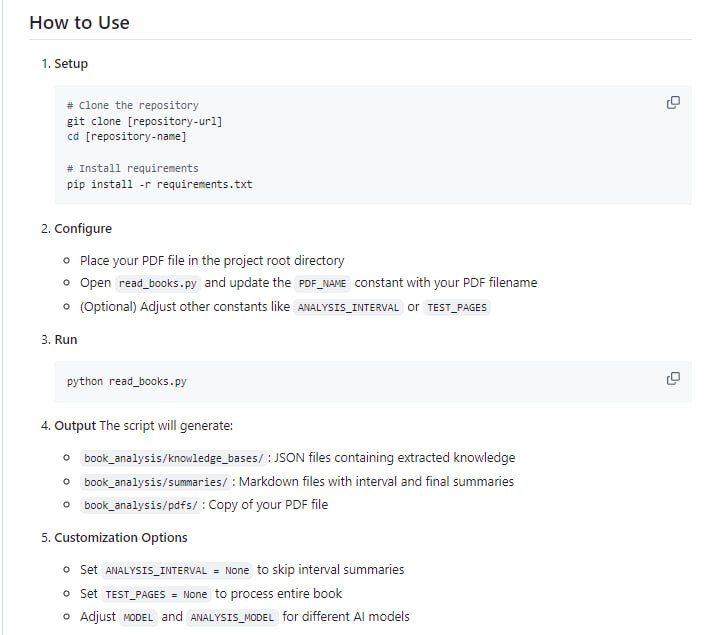
read_books.py 的核心功能是模拟真人阅读过程,对 PDF 书籍进行智能逐页解读。其工作流程主要包含以下几个关键环节:
- 智能逐页解析与知识提取:工具利用 AI 驱动的内容理解能力,自动分析每一页内容,识别并提取其中的关键知识点,帮助用户聚焦重点。
- 阶段性总结生成:在阅读过程中,工具会定期(可根据配置调整间隔)生成阶段性总结,让用户能够及时回顾阅读进度和已获取的核心内容。
- 结构化笔记管理:所有提取的知识点和生成的总结均以 Markdown 格式保存,并组织在结构化的输出目录中,便于后续的查找、编辑与整合。
此外,该工具还提供了一系列增强用户体验的辅助功能,包括支持断点续读、智能过滤目录和索引等非核心内容、灵活的配置选项(如调整分析间隔),以及在终端中以彩色显示重要信息等。
价值与影响
read_books.py 工具的价值在于将 AI 能力与文档处理流程相结合,实现了阅读与笔记整理的自动化。它能够解放用户在信息筛选和初步整理上的时间,使其更专注于深度思考与知识内化。对于需要大量阅读文献的研究人员、学生以及任何希望构建个人知识库的用户而言,这类工具提供了一种高效、结构化的信息处理方案,有助于提升学习与工作效率。





