CocoIndex:Rust 与 Python 构建的高效数据处理框架
TechFoco 精选
CocoIndex 是一个结合 Rust 引擎与 Python 声明式编程的数据处理框架,支持增量处理、数据血缘追踪,并能轻松构建向量索引和知识图谱。
在 AI 应用与数据密集型系统开发中,构建高效、可维护的数据处理管道是一项核心挑战。传统方法常受限于 SQL 的表达能力或复杂的状态管理。CocoIndex 框架旨在通过结合 Rust 的性能与 Python 的易用性,为开发者提供一个现代化的解决方案。
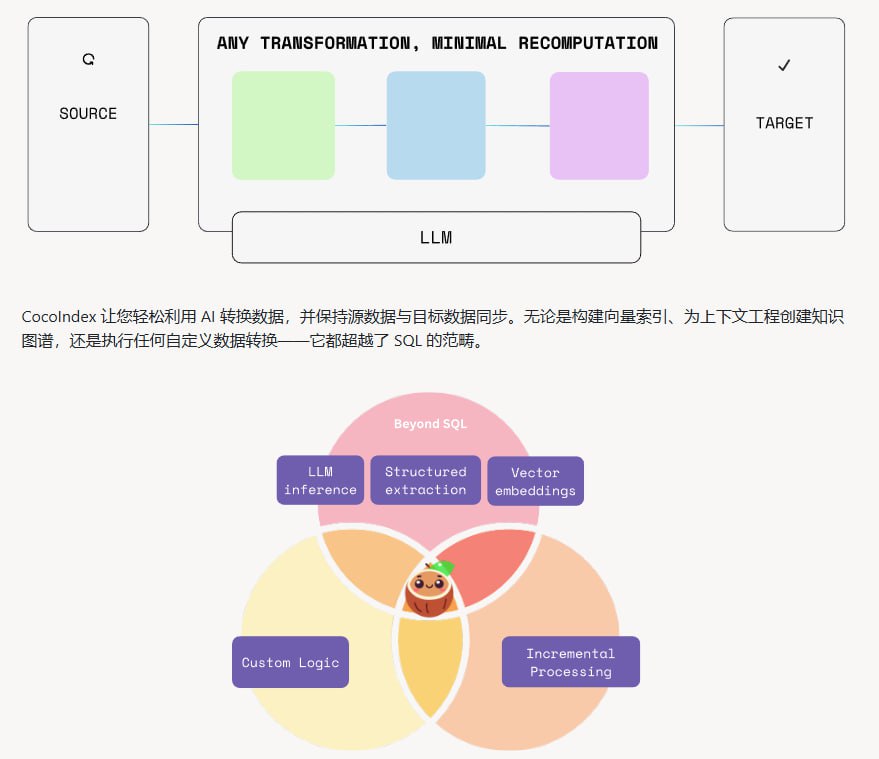
核心内容
CocoIndex 的核心引擎采用 Rust 语言编写,专注于实现高效的增量处理与精确的数据血缘追踪。这使得开发者能够从项目初期就将框架投入生产环境,确保数据处理的可观测性与可靠性。
在编程接口层面,框架允许开发者使用约 100 行 Python 代码以声明式的方式构建复杂的数据流。这种设计超越了传统 SQL 的局限,能够轻松实现向量索引构建、知识图谱生成以及各种自定义的数据转换任务。
其技术特点主要包括:
- 基于数据流编程模型,所有数据变化全程可观察,避免了隐式状态或值的意外变异。
- 原生支持多种数据源、处理目标和转换组件,组件间的切换与组合如同拼接积木般简单。
- 能够自动保持源数据与目标数据的同步,从而实现高效的增量索引更新和缓存复用。
- 兼容 Postgres 数据库,并支持将处理结果导出到向量数据库和图数据库。
- 提供详细的文档和丰富的示例,帮助开发者快速上手。
价值与影响
CocoIndex 为需要构建语义搜索、上下文工程以及实时数据管道的开发者和团队提供了一个强有力的工具。它通过将高性能的 Rust 引擎与灵活的 Python API 相结合,在保证处理效率的同时,大幅降低了构建和维护复杂数据流水线的门槛。该框架对数据血缘的原生支持,也有助于提升数据治理水平与系统的可调试性。





