The Well:15TB 物理仿真数据集发布
TechFoco 精选
The Well 开源项目发布了总量达 15TB 的高质量物理仿真数据集,涵盖生物系统、流体力学等多个领域,并提供 Python 接口与基准模型,旨在支持机器学习与计算科学的研究。
在机器学习和计算科学领域,高质量、大规模的训练数据是推动模型发展的关键。尤其在物理仿真等科学计算任务中,获取覆盖多领域、高精度的模拟数据一直存在挑战。近日,由多所知名科研机构联合开发的开源项目 The Well 正式发布,旨在为相关研究提供数据基础。
核心内容
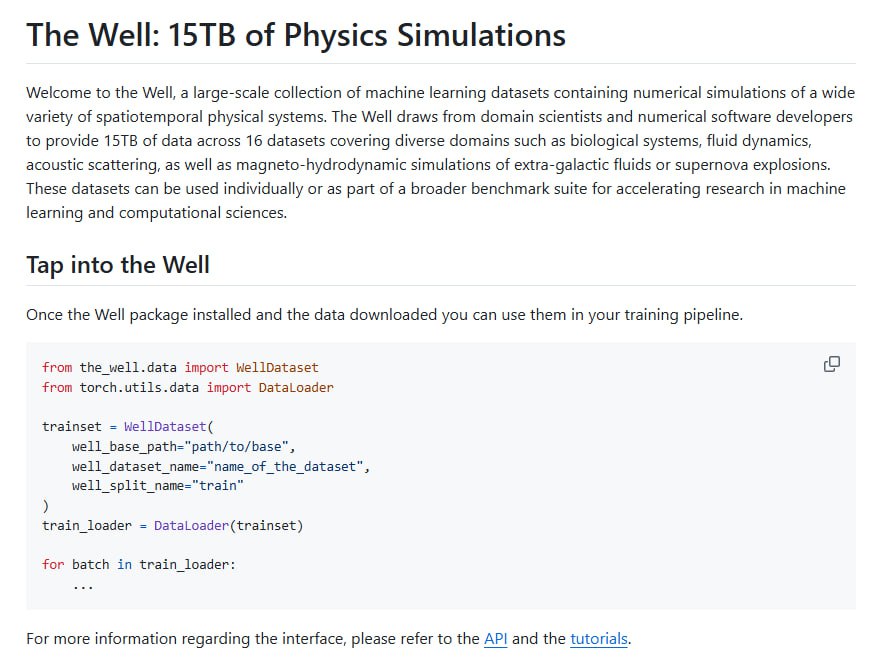
The Well 项目集成了 16 个不同的数据集,构成了总量高达 15TB 的物理仿真数据集合。这些数据涵盖了生物系统、流体力学、声波散射、磁流体动力学等多个物理领域,均为高精度仿真结果。
在数据访问与使用层面,项目提供了灵活的方案。用户可以选择直接下载数据到本地,也可以通过 Hugging Face 平台进行流式访问。项目配套了易用的 Python 接口,特别是与 PyTorch 框架深度集成,可以便捷地加载数据用于模型训练。
此外,The Well 不仅提供原始数据,还包含了基准测试(Benchmark)和预训练模型。这一设计方便研究人员进行性能对比与模型迭代,快速验证和改进针对物理场数值模拟或偏微分方程(PDE)代理模型的新方法。
价值与影响
该项目为机器学习研究者、物理模拟开发者和计算科学团队提供了一个规模空前的标准化数据资源。其由权威机构联合开发,保障了数据的质量与可靠性。通过降低高质量仿真数据的获取与使用门槛,The Well 有望加速跨学科的 AI 科研创新,特别是在科学机器学习(Scientific Machine Learning)领域,为开发更精准、高效的物理仿真模型奠定坚实的数据基础。