DeepOCR:完全开源复现 DeepSeek-OCR 训练过程
TechFoco 精选
DeepOCR 是由爱荷华州立大学和普林斯顿大学发起的开源项目,旨在提供完整的代码以复现 DeepSeek-OCR 的训练与评估流程,而不仅仅是权重和报告。
在计算机视觉领域,光学字符识别(OCR)技术是文档数字化和理解的关键。近期,DeepSeek-OCR 模型因其出色的性能受到关注,但其官方开源内容主要包含预训练权重和技术报告,完整的训练过程复现对于研究者和开发者而言仍存在一定门槛。
核心内容
为降低复现难度并促进相关研究,来自爱荷华州立大学和普林斯顿大学的研究人员发起了 DeepOCR 项目。该项目并非简单的代码移植,而是一个旨在完全复现 DeepSeek-OCR 训练过程的开源工程。
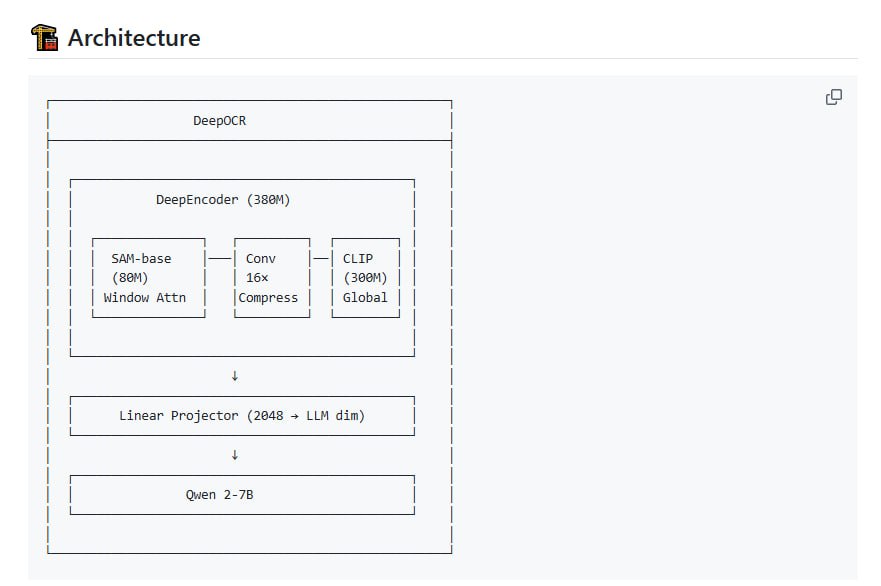
与仅提供权重的版本不同,DeepOCR 项目提供了从数据准备、模型训练到最终评估的完整代码链。这使得研究人员和工程师能够深入理解模型构建的每一个环节,包括:
- 训练流程的具体实现
- 评估指标的计算方法
- 相关的数据处理与增强策略
通过访问其 GitHub 仓库,开发者可以获得一套可运行、可修改的代码基础,从而在 DeepSeek-OCR 的工作上进行进一步的实验、优化或适配到特定场景。
价值与影响
DeepOCR 项目的出现,为 OCR 社区提供了重要的实践资源。它降低了复现前沿工作的技术壁垒,使更多团队能够验证、学习并基于现有成果进行创新。完整的训练代码也有助于提升研究的可复现性,这是推动科学进步的关键因素。对于希望在特定领域(如复杂版面、手写体或多语言)定制 OCR 模型的开发者而言,该项目提供了一个坚实的起点。
来源:黑洞资源笔记