olmOCR 2:开源高效文档转换工具
TechFoco 精选
olmOCR 2 是一款开源的文档转换工具,专注于将 PDF 及多种格式文档精准转换为纯文本,支持表格、公式等复杂元素。通过结合高质量数据训练与强化学习奖励机制,有效降低了识别中的“幻觉”错误。
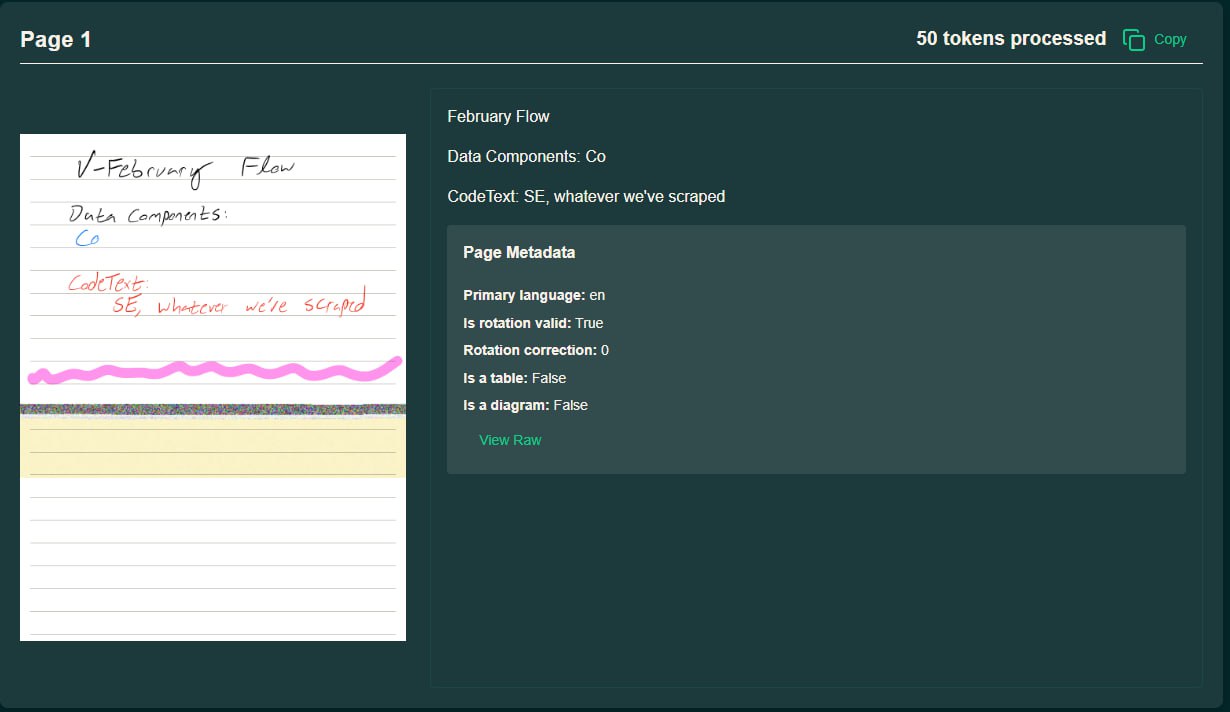
文档数字化是科研、教育和档案管理等领域的基础性工作。传统的 OCR 技术在处理包含表格、公式或手写内容的复杂文档时,常面临格式错乱、识别错误等挑战。olmOCR 2 作为一款开源工具,旨在通过先进的多模态模型技术,提供更精准、高效的文档转换解决方案。
核心内容
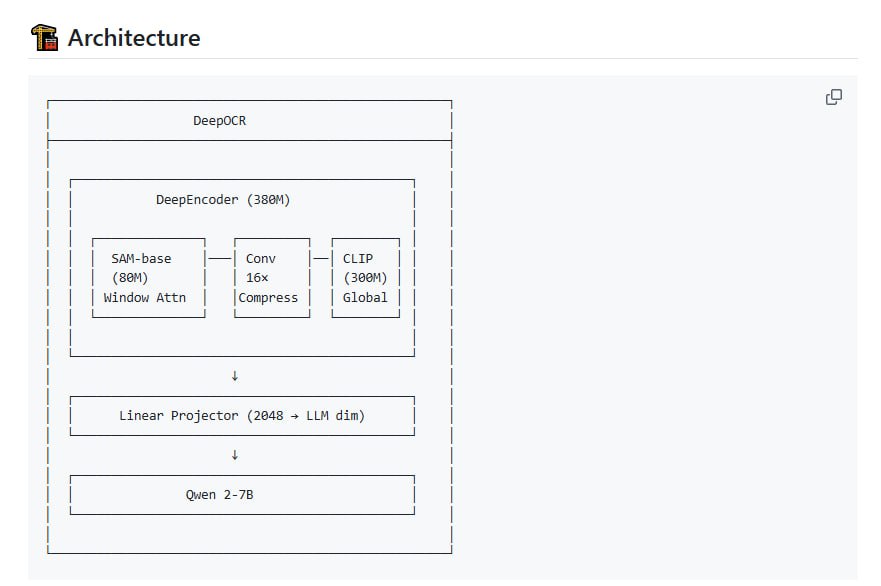
olmOCR 2 的核心功能是将 PDF 及多种格式的文档精准转换为纯文本,并保持自然的阅读顺序。其技术实现基于多语言视觉语言模型进行微调,主要针对英文文档进行了优化,同时也具备处理其他语言文档的兼容能力。
该工具的技术亮点在于其训练策略。它基于大量精选的学术论文、技术文档等高质量数据进行训练,并创新性地结合了合成数据与强化学习中的单元测试奖励机制。这一方法旨在从模型内部减少输出中的“幻觉”错误,从而显著提升了识别的准确率与可靠性。
在部署方式上,olmOCR 2 提供了灵活性。用户可以直接在线体验其基本功能,也可以选择在自有 GPU 环境上部署完整的工具包。这种本地化部署方案支持高效、可扩展的批量文档处理任务,有助于控制长期使用成本。
价值与影响
olmOCR 2 的出现,为需要处理大量复杂文档的领域提供了强有力的技术支持。在科研中,它有助于快速提取和分析文献数据;在教育领域,可以辅助教材和资料的数字化;在档案管理方面,则能推动历史文档的系统性数字化保存。通过提升文档转换的准确性和自动化水平,该工具推动了整个文档处理流程向更精准、更智能的方向发展。