bRAG-langchain:系统性掌握 RAG 技术的开源指南
TechFoco 精选
本文介绍 bRAG-langchain 开源项目,该项目通过一系列 Jupyter Notebook 提供了从查询构建、检索优化到生成环节的完整 RAG 技术栈实操指导,旨在帮助开发者系统性地掌握检索增强生成技术。
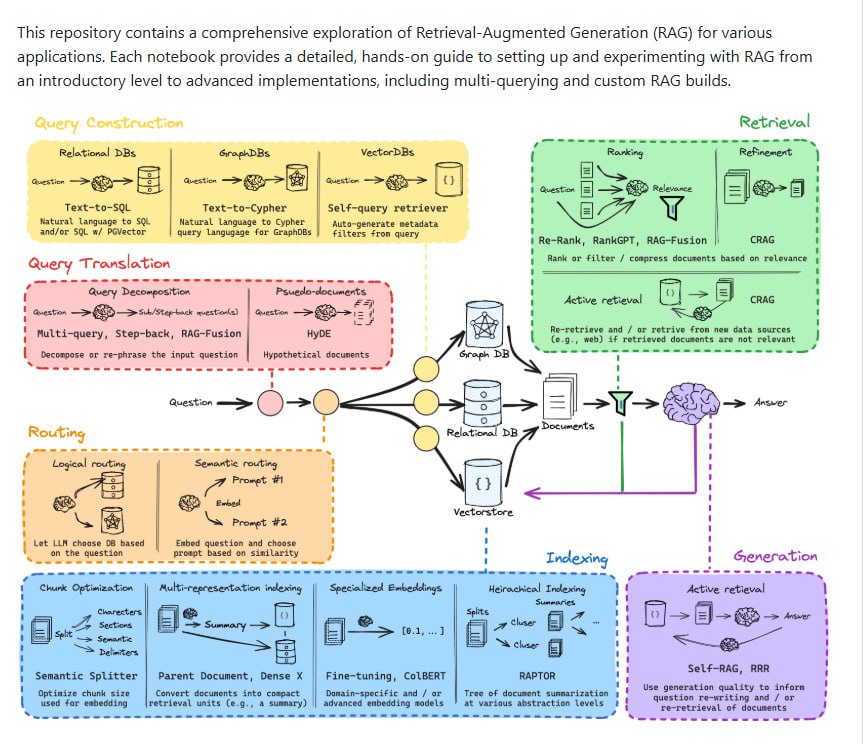
检索增强生成(Retrieval-Augmented Generation, RAG)已成为连接大型语言模型与外部知识库的关键技术,旨在提升模型回答的准确性与时效性。然而,构建一个高效、可靠的 RAG 系统涉及查询处理、检索、索引管理及生成优化等多个复杂环节,对开发者提出了较高要求。
核心内容
bRAG-langchain 是一个开源项目,旨在通过结构化的 Jupyter Notebook 教程,系统性地引导开发者掌握 RAG 技术的核心组件与实践方法。
项目内容主要涵盖以下几个关键模块:
- 查询构建与翻译:指导如何将自然语言问题转化为结构化查询,例如 SQL、Cypher 或向量检索查询。同时,通过查询分解与重构技术,优化原始输入以提升检索效果。
- 路由与检索优化:介绍动态选择知识库或嵌入上下文的路由机制,以精准定位答案来源。在检索环节,项目整合了多种重排序算法,并支持实时数据接入,以确保返回结果的相关性。
- 索引管理:探讨了通过多重表征嵌入、分层摘要和结构化搜索等技术来提升索引构建与查询效率的方法。
- 生成与迭代优化:项目包含了自研的 Self-RAG 和 RRR(Retrieve, Read, Rerank)方法,旨在实现推理过程与检索行为的迭代闭环,从而提升最终生成答案的质量。
每个模块都配有详细的代码示例与实操指导,支持从基础到进阶的学习路径,并覆盖了多查询、多模态等高级应用场景。
价值与影响
该项目为学习和实践 RAG 技术提供了一个结构清晰、内容全面的开源资源。它系统化地梳理了 RAG 工作流中的关键技术点,并提供了可运行的代码,有助于开发者理解理论并快速进行原型验证。对于从事机器学习、大语言模型应用或 AI 智能体开发的工程师而言,此类资源能够显著降低构建复杂 RAG 应用系统的初始门槛。
从更宏观的视角看,该项目的实践也反映出当前 RAG 技术发展的一个共识:系统的效能不仅取决于架构设计,更依赖于高质量数据的积累与对语料空白的有效补充。未来,递归推理能力与动态语料更新机制,或将成为推动 RAG 系统性能实现关键突破的重要方向。
来源:黑洞资源笔记



