docext:无需OCR的本地文档信息提取工具
TechFoco 精选
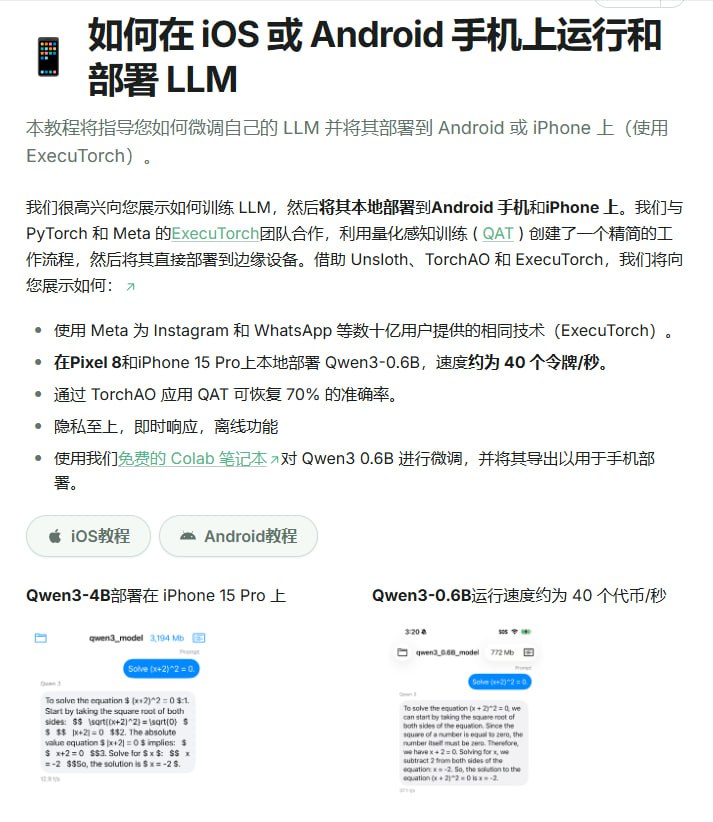
docext 是一款基于视觉语言模型的文档信息提取工具,无需依赖传统OCR技术即可从文档中提取结构化信息。它支持完全本地化部署、多页文档处理,并提供REST API接口以便集成。
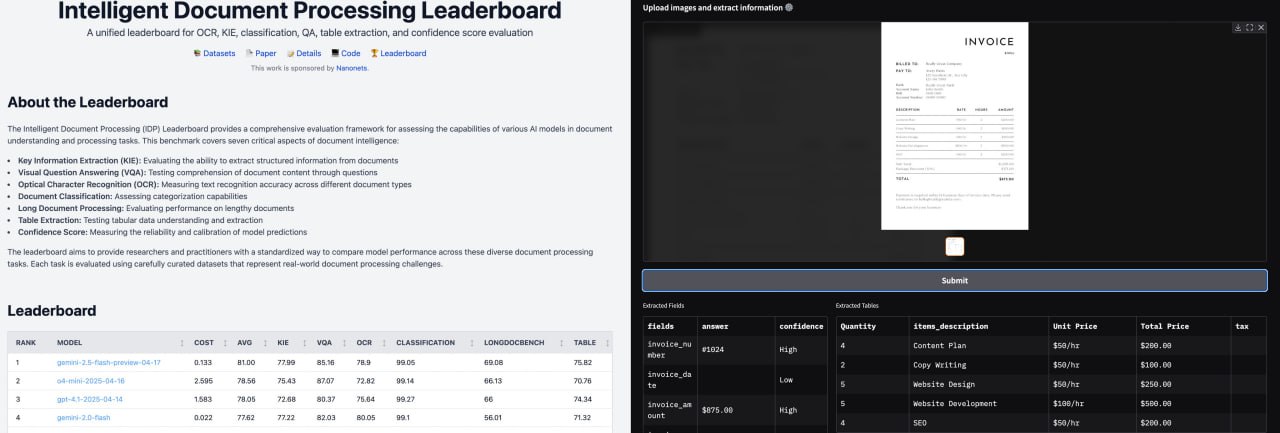
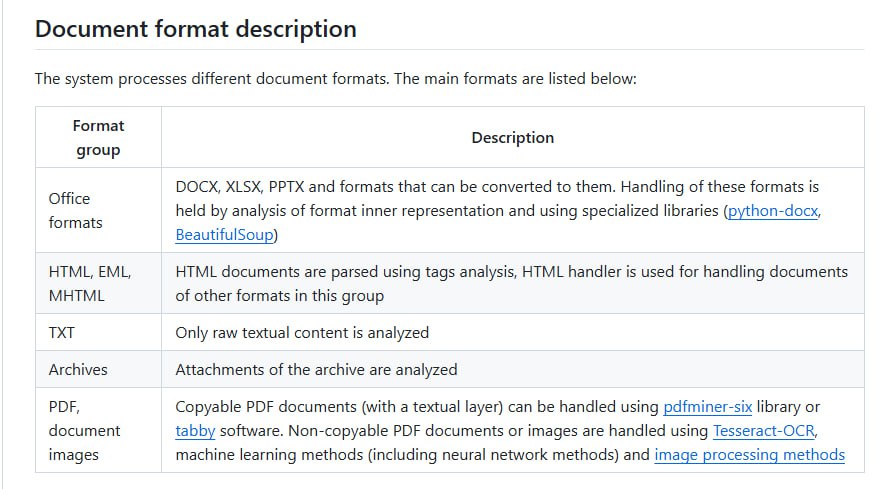
在文档数字化和信息处理领域,传统方法通常依赖于光学字符识别技术。然而,OCR在处理复杂版式或非标准字体时可能面临挑战。近期,一种基于视觉语言模型的新兴方案提供了替代路径。
核心内容
docext 是一款利用视觉语言模型进行文档信息提取的工具。其核心特点在于绕过了传统的OCR流程,直接从文档图像中理解和提取结构化信息。该工具支持完全本地化部署,这意味着数据处理过程无需离开用户本地环境,有助于满足对数据隐私和安全有严格要求的场景。
在功能层面,docext 能够处理多页文档,适应包含表格、图表等复杂元素的文件。同时,它提供了标准化的REST API接口,允许开发者将其功能无缝集成到现有的业务流程或应用系统中。
价值与影响
这种无需OCR的提取方式,为文档信息自动化处理提供了新的技术思路。本地部署的特性使其适用于金融、医疗等对数据敏感性要求高的行业。REST API的设计则降低了集成门槛,便于企业将其纳入现有技术栈,提升文档处理流程的效率和智能化水平。