NewsNow:优雅的实时新闻阅读与同步工具
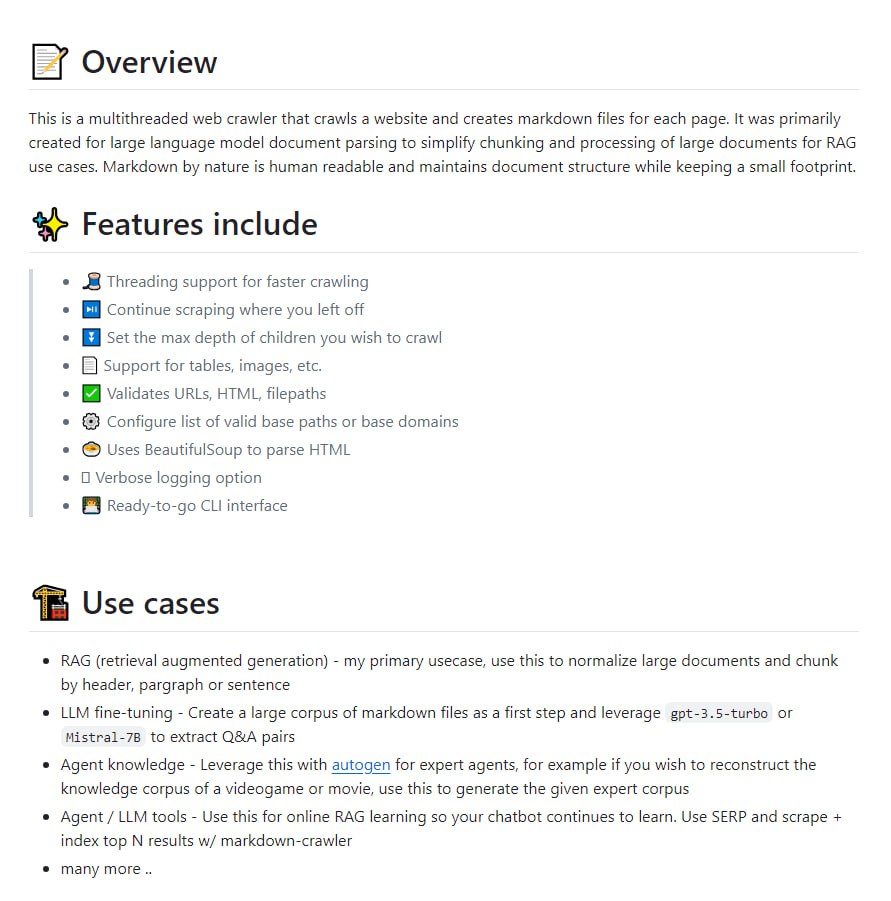
NewsNow 是一个实时新闻聚合工具,提供优雅的阅读体验,支持通过 GitHub 登录实现数据同步,并采用智能爬虫策略以平衡数据新鲜度与资源消耗。
在信息过载的时代,高效获取并同步阅读实时新闻成为许多用户的需求。NewsNow 项目旨在提供一个设计优雅、体验流畅的新闻聚合平台,帮助用户专注于最新、最热门的新闻内容。该项目通过整合 GitHub 登录与数据同步功能,试图解决多设备间阅读进度与偏好的统一问题。
核心内容
NewsNow 的核心功能围绕优雅的阅读体验与智能的数据获取机制展开。
首先,在用户体验层面,项目强调优雅的设计与阅读体验,致力于让用户能够舒适、高效地浏览实时热门新闻。
其次,在数据同步方面,项目支持用户通过 GitHub 账户登录。这一设计不仅简化了注册流程,更重要的是实现了用户阅读数据(如偏好、历史记录)在不同设备间的同步,提升了使用的连贯性。
最后,在技术实现上,项目采用了兼顾效率与稳定性的数据更新策略。系统默认对新闻内容设置 30 分钟的缓存,以提升访问速度并减少后端负载。对于已登录的用户,系统提供了强制拉取最新数据的选项,以满足对信息即时性的更高要求。更为关键的是,其后台爬虫策略并非固定不变,而是根据各个内容源本身的更新频率,动态调整爬取间隔——最快可达两分钟。这种差异化策略在尽可能保证新闻新鲜度的同时,有效节约了计算资源,并降低了因请求过于频繁而导致 IP 地址被目标网站封禁的风险。
价值与影响
NewsNow 项目的价值在于其将优雅的用户体验与务实的技术策略相结合。通过 GitHub 集成,它降低了用户使用门槛并解决了数据孤岛问题。其智能化的爬虫间隔设置,则展示了一种在数据新鲜度、资源消耗和操作安全性之间寻求平衡的工程思路,这对于开发类似的数据聚合或爬虫应用具有参考意义。该项目为追求简洁、同步阅读体验的用户提供了一个潜在的技术解决方案。
来源:Parry