LLM 优化指南 内存 计算 推理 技术
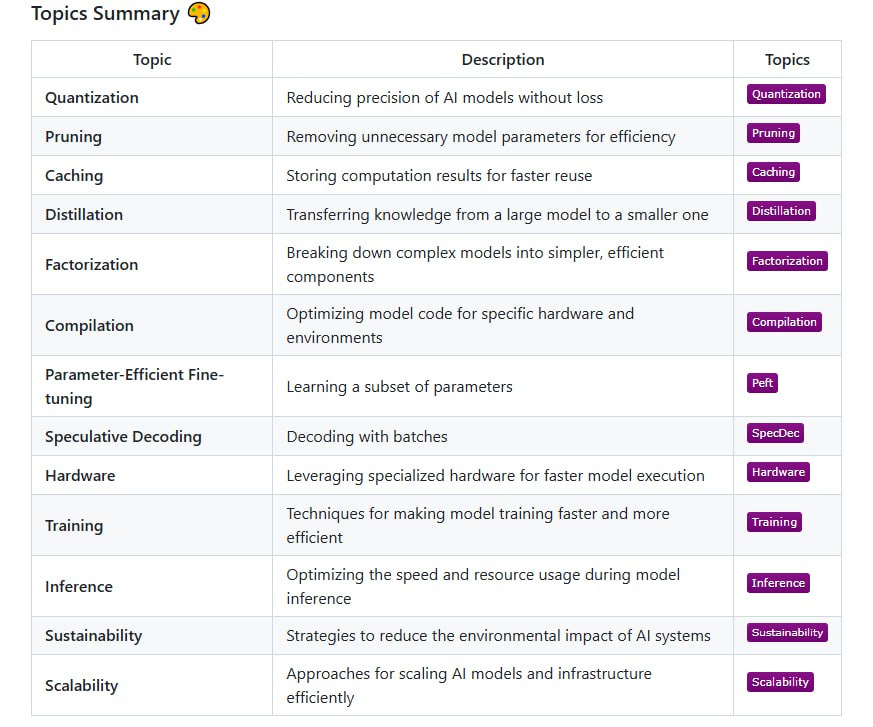
LLM优化三大方向:显存优化(Flash Attention/激活检查点)、计算优化(序列打包/高效Transformer)、推理优化(KV缓存/量化技术)。涵盖训练与推理全流程关键技术。
随着大型语言模型的参数规模突破数十亿甚至万亿级别,传统的训练和部署方法面临着前所未有的挑战。这些挑战主要体现在显存占用、计算复杂度和推理效率三个关键维度。本文系统性地梳理了当前业界主流的优化技术,涵盖内存优化、计算优化和推理优化三大核心方向,为对大模型优化感兴趣的技术人员和研究人员提供全面的技术参考。
显存优化技术深度剖析
在显存优化领域,Flash Attention 技术通过创新的"切块计算与重算"机制,成功将注意力机制的内存复杂度从二次方降低到线性级别。该技术将传统的全矩阵处理方式转变为分块处理策略,仅需保存归一化因子而非完整的注意力矩阵,从而显著减少了训练过程中的显存占用。多查询注意力机制则通过共享键值向量的方式进一步优化内存使用,其中分组查询注意力在效率和模型质量之间实现了精妙平衡。激活检查点技术采用选择性保存策略,仅保留部分关键激活值,在反向传播过程中重新计算其余激活,这种方法虽然增加了少量计算开销,但极大地缓解了显存压力。
计算优化策略全面解析
计算优化方面,序列打包技术通过将多条训练序列智能拼接,彻底消除了传统填充方法带来的计算浪费,大幅提升了 GPU 计算单元的利用率。高效的 Transformer 架构改进,如 BigBird 和 Longformer 等模型,通过结合局部注意力和全局注意力机制,实现了对长序列输入的线性复杂度处理。低秩近似技术和层级扩张注意力机制则从数学原理层面出发,通过矩阵分解和注意力模式优化,进一步降低了计算复杂度,为处理更大规模输入提供了技术基础。
推理优化方法深入探讨
推理阶段的优化同样至关重要。KV 缓存技术通过缓存历史键值对,避免了在生成过程中对已计算内容的重复处理,既提升了推理速度又优化了内存使用效率。状态缓存机制则采用滚动哈希和 LRU 算法等先进技术来管理对话历史,支持跨会话的缓存复用。推测解码技术引入了一个创新的双模型协作框架:首先使用轻量级模型快速生成候选序列,然后由主模型进行验证和修正,这种方法在实际应用中能够实现 2-3 倍的推理速度提升。量化技术体系包括 8 位量化、混合精度计算和量化感知训练等多种方法,在保证模型精度的前提下实现了模型体积的显著压缩。
训练优化体系完整阐述
训练优化是一个多层次的系统工程。混合精度训练巧妙结合了 bfloat16 的数据格式和动态损失缩放技术,在保持数值稳定性的同时获得了显著的速度提升。数据并行与 ZeRO 优化技术通过智能分割模型参数、梯度和优化器状态,实现了显存使用的极限压缩。流水线并行架构如 GPipe 和 PipeDream 等,通过精细的任务调度减少了 GPU 空闲时间,支持多阶段模型的并行执行。张量并行技术采用列切分和行切分的矩阵乘法策略,实现了大模型跨设备的高效计算。上下文并行将序列长度分割到多个 GPU 上,结合先进的通信协议保证了计算效率。专家并行模型通过引入专家子网络架构,将不同的 token 路由到不同的专家模块进行处理,在显著扩展模型容量的同时,也需要精心设计负载均衡机制来确保各专家模块的均衡利用。
优化大型语言模型是一项复杂的系统工程,需要在内存占用、计算效率和通信开销之间寻求最佳平衡点。本文汇总的核心技术代表了当前业界最前沿的优化思路,有助于深入理解大模型训练与推理过程中的关键瓶颈及其解决方案。随着模型规模的持续增长,这些优化策略的重要性将日益凸显,为下一代超大规模型的发展奠定坚实的技术基础。
原文链接: Large Language Model Optimization: Memory, Compute, and Inference Techniques