MM_StoryAgent:沉浸式故事书视频生成的多Agent框架
本文介绍了 MM_StoryAgent,一个用于生成沉浸式故事书视频的多智能体框架。该框架支持基于设定进行高质量故事创作,并整合图像、语音、音效和音乐等多模态内容生成,同时允许用户通过自定义工作流提升生成质量。
随着多模态人工智能技术的快速发展,如何将文本、图像、音频等多种媒体形式有机融合,以创造连贯、沉浸式的叙事体验,成为研究与应用的热点。传统的单一模型或流水线在处理此类复杂、创意性的任务时,往往在内容一致性、多样性和可控性上面临挑战。多智能体系统通过模拟分工协作,为解决这一问题提供了新的思路。
核心内容
MM_StoryAgent 是一个专为沉浸式故事书视频生成而设计的多智能体框架。其核心设计理念是将复杂的视频生成任务分解,由多个具备特定能力的智能体协同完成。
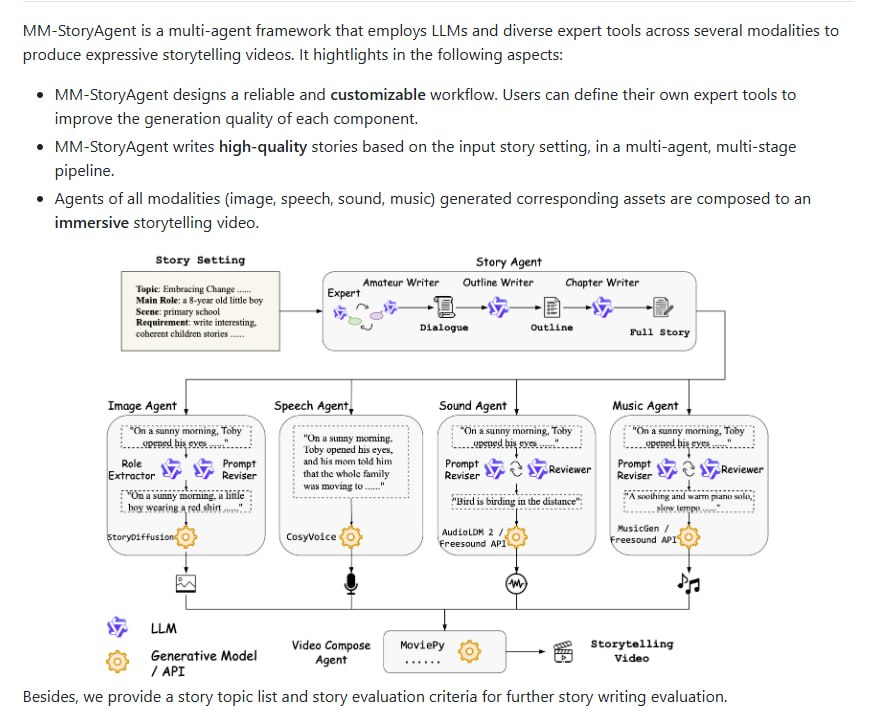
该框架的核心功能主要体现在三个方面。首先,它支持高质量的故事创作。系统能够基于用户输入的故事设定,生成结构完整、情节丰富的故事文本,为后续的多媒体内容生成奠定基础。其次,它实现了多模态内容生成。框架能够根据生成的故事,自动创建配套的图像、语音、音效和背景音乐,构建一个立体的感官体验。最后,它提供了可定制的工作流。用户可以根据具体需求,定义和集成不同的专家工具或模型,以优化特定环节的生成质量,增强了框架的灵活性和适应性。
价值与影响
MM_StoryAgent 框架的价值在于其系统化的多智能体协作模式。它将故事生成、视觉呈现和听觉渲染等多个子任务模块化,并通过智能体间的交互来保证最终作品在叙事逻辑和感官体验上的一致性。这种架构不仅提升了生成内容的整体质量,也为用户提供了更高程度的控制权,允许通过定制工作流来满足不同风格或精度的要求。
该框架为自动化内容创作,特别是在教育、娱乐和数字出版领域,提供了一种新的技术路径。它展示了多智能体系统在复杂创意任务中的潜力,推动了多模态生成技术向更集成、更可控的方向发展。

