Baichuan-M1-14B:专为医疗场景优化的开源大语言模型
TechFoco 精选
百川智能发布了首个专为医疗场景优化的开源大语言模型 Baichuan-M1-14B。该模型基于 20 万亿 token 高质量数据训练,医疗推理能力显著提升,并采用创新结构以优化长序列任务处理。
随着人工智能技术在医疗领域的深入应用,对专业、精准且高效的语言模型需求日益增长。通用大语言模型在处理复杂医疗文本、专业术语和长序列推理任务时,往往面临精度和效率的挑战。为此,针对特定垂直领域进行深度优化的模型成为行业发展的关键方向之一。
核心内容
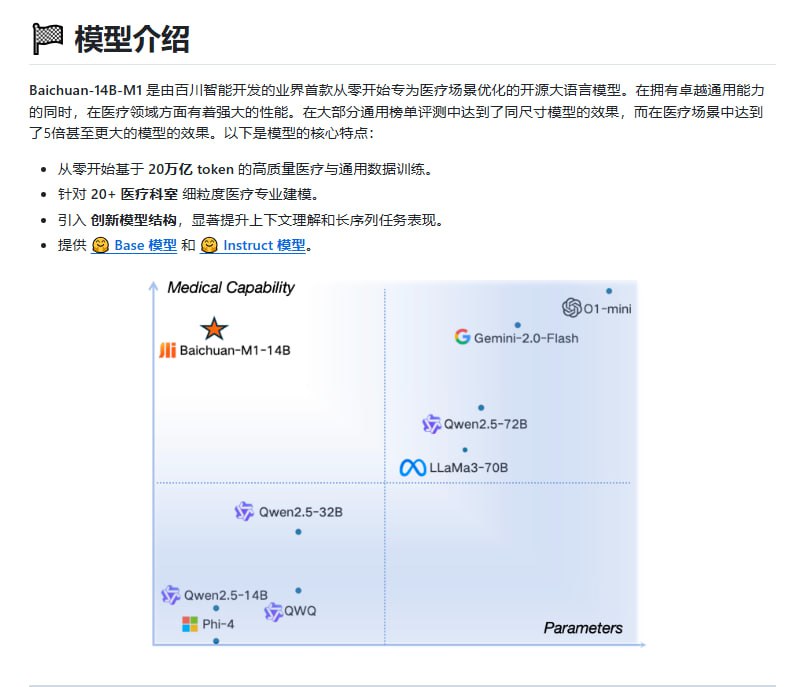
百川智能近期开源了其首个专为医疗场景优化的大语言模型 Baichuan-M1-14B。该模型旨在通过针对性的训练和结构设计,提升在医疗领域的智能化应用能力。
模型的核心技术特点主要体现在以下几个方面:
- 大规模高质量数据训练:Baichuan-M1-14B 使用了高达 20 万亿 token 的医疗相关高质量数据进行训练,为其卓越的性能奠定了基础。
- 医疗推理能力显著增强:据官方信息,该模型在医疗场景下的推理能力相比基准模型提升了 5 倍,在处理医学问答、诊断辅助等任务时更加精准和高效。
- 创新模型结构:模型采用了创新的架构设计,特别优化了对于长序列任务的处理能力,使其在分析长篇医疗文献、病历记录等场景中表现更为出色。
价值与影响
Baichuan-M1-14B 的开源为医疗 AI 社区提供了新的工具选择。其针对医疗场景的深度优化,有望直接赋能临床辅助决策、医学研究、智能问诊和健康管理等多个应用环节,推动医疗领域智能化解决方案的落地与升级。作为一个开源项目,它也降低了相关技术的研究与应用门槛,有助于促进更广泛的协作与创新。