Crawl4AI:专为 LLM 设计的开源网页爬虫工具
TechFoco 精选
Crawl4AI 是一款开源的网页爬虫与抓取工具,其核心设计理念是生成对大型语言模型友好的结构化数据,以优化后续的 AI 处理与分析流程。
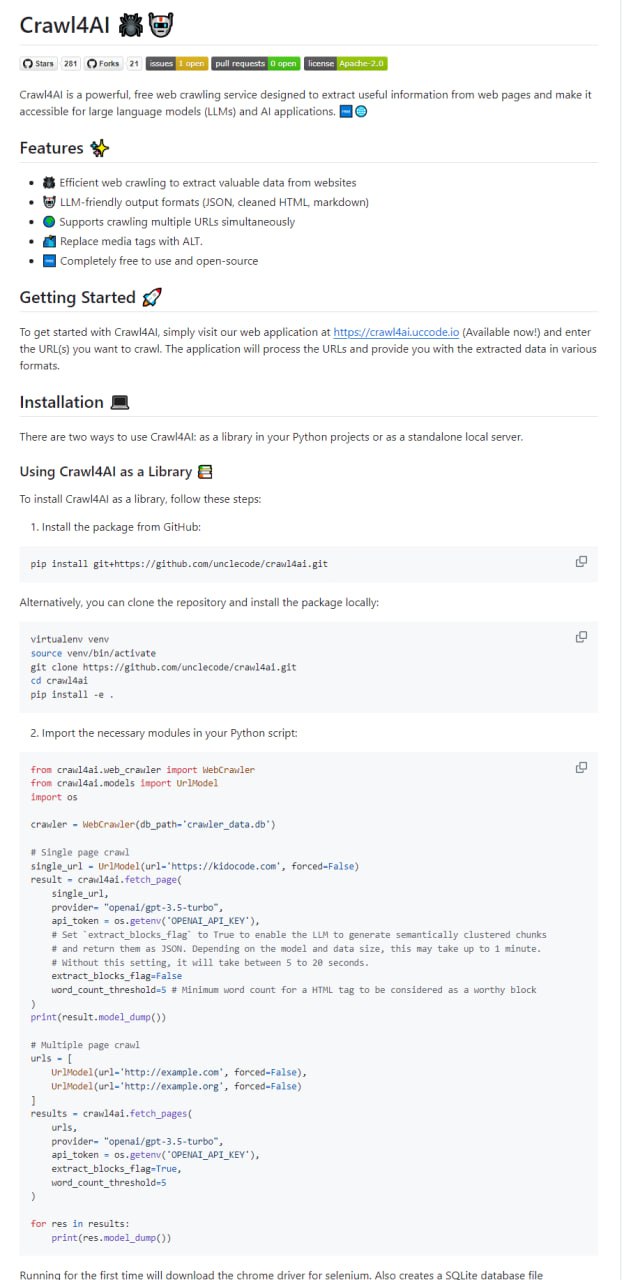
在利用大型语言模型(LLM)进行信息处理与分析时,高质量、结构化的数据输入至关重要。传统的网页爬虫工具获取的内容往往包含大量无关的 HTML 标签、广告脚本和冗余格式,这些噪声会直接影响 LLM 的理解与生成效果。因此,开发一款能够为 LLM 提供“友好”数据源的专用爬虫工具,成为提升 AI 应用效能的一个实际需求。
核心内容
Crawl4AI 正是为应对这一挑战而设计的开源工具。它并非一个通用的网页爬虫,其核心目标是从网页中提取并生成对大型语言模型(LLM)友好的内容。这意味着它在抓取网页时,会着重处理并优化文本的结构与格式,例如智能地剥离无关的页面元素、保留语义清晰的段落和列表、以及可能进行初步的内容清洗与归一化,旨在输出更干净、更易于 LLM 消化和处理的文本数据。
价值与影响
Crawl4AI 的出现,为依赖 LLM 进行网络信息挖掘、知识库构建或内容分析的项目提供了更专业的数据获取方案。通过提供专门优化的数据源,它有助于减少后续数据清洗的工作量,并可能提升 LLM 在特定任务上的准确性和效率。作为一个开源项目,它也允许开发者根据自身需求进行定制和扩展,进一步推动了 AI 与数据获取工具链的整合。




