Fish Speech:全新的文本转语音解决方案
Fish Speech 是一个全新的文本转语音解决方案,强调高度自定义和灵活性,支持 Linux 和 Windows 系统,推理需 2GB GPU 内存,并采用 Flash-Attn 及支持 VQGAN 与 Tex...
文本转语音技术是人工智能领域的重要分支,广泛应用于语音助手、有声内容创作和辅助工具等场景。随着对语音自然度和系统灵活性的要求不断提高,开发者社区持续探索新的技术方案。Fish Speech 作为一个新近出现的开源项目,旨在提供一种高度可定制且灵活的 TTS 解决方案。
核心内容
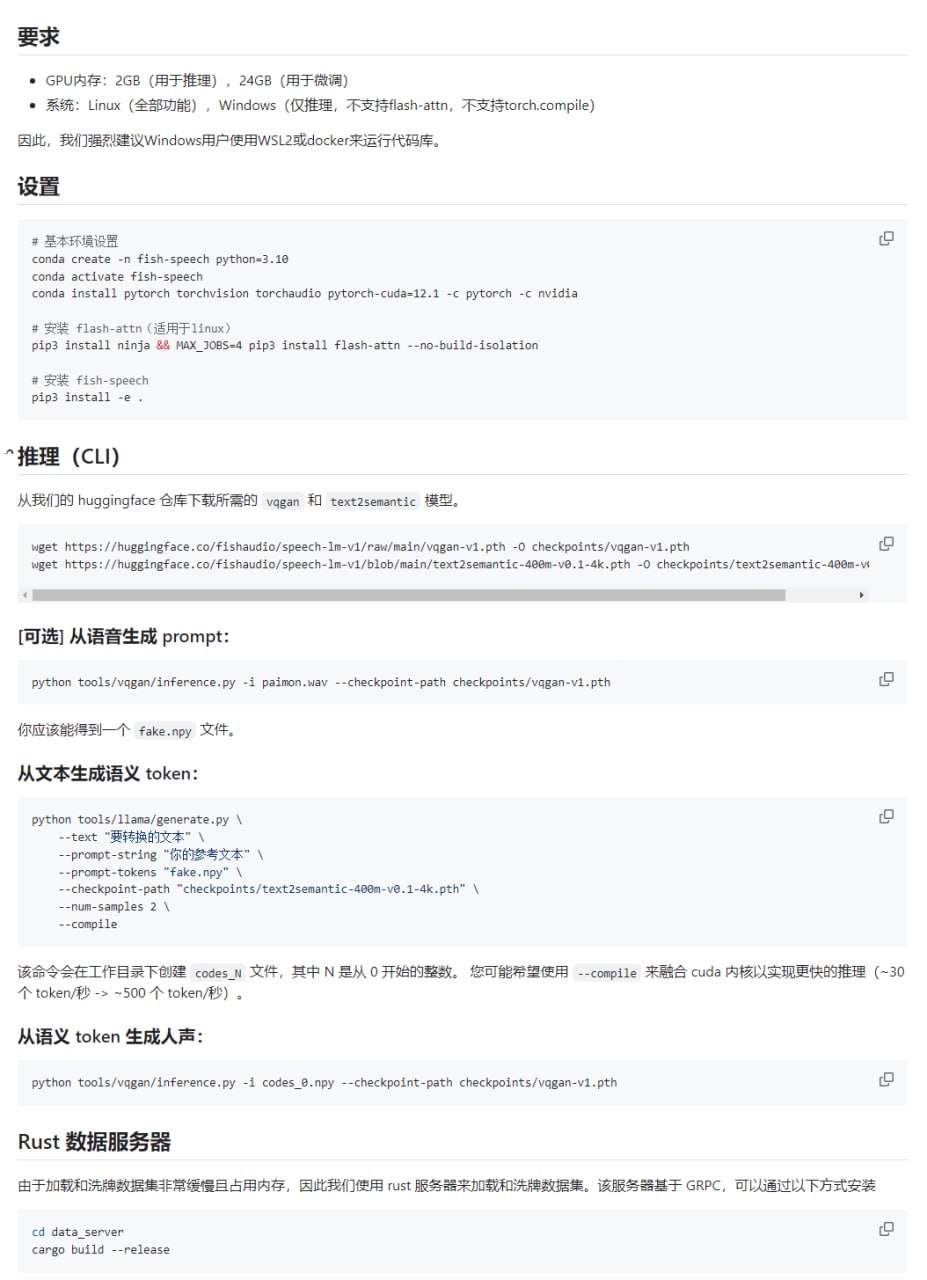
Fish Speech 的核心特性体现在其架构设计与技术实现上。该项目支持在 Linux 和 Windows 操作系统上运行,为不同平台的开发者提供了便利。在硬件需求方面,进行推理时需要至少 2GB 的 GPU 内存,这为在消费级硬件上部署提供了可能性。
在技术栈上,Fish Speech 采用了 Flash-Attn 机制来优化推理和训练过程,这有助于提升计算效率。同时,该项目支持两种模型架构:VQGAN 和 Text2Semantic。VQGAN 通常用于高质量音频的生成,而 Text2Semantic 模型则侧重于从文本到语义表示的转换,二者的结合为生成自然、可控的语音提供了技术基础。这些设计共同构成了其高度自定义和灵活性的特点。
价值与影响
Fish Speech 的出现为 TTS 研究和应用开发社区提供了一个新的选择。其开源特性允许研究人员和开发者深入探究模型细节,并根据特定需求进行定制化修改。对 VQGAN 和 Text2Semantic 模型的支持,意味着开发者可以基于不同的生成路径进行实验,探索语音合成质量与可控性之间的平衡。较低的 GPU 内存需求也降低了入门门槛,有助于技术的普及和更广泛的原型验证。总体而言,该项目为推进个性化、高质量的语音合成技术发展贡献了工具和思路。