ScrapeGraphAI 革新爬虫技术 5 行代码玩转智能数据抓取
ScrapeGraphAI:基于LLM和图逻辑的智能爬虫库,支持多模式数据提取,兼容主流平台,简单高效开源。
在当今数据驱动的时代,高效获取和处理网络数据已成为开发者和数据分析师的必备技能。传统爬虫技术虽然成熟,但往往需要编写大量规则代码,难以应对动态变化的网页结构。ScrapeGraphAI 应运而生,这个开源 Python 库巧妙结合了大型语言模型(LLM)与图逻辑,为数据提取带来了革命性的智能解决方案。
核心架构与工作原理
ScrapeGraphAI 的核心创新在于其"语言理解+图结构"的双重策略。不同于传统基于规则的爬虫,它利用 LLM(如 OpenAI、Ollama 等)的自然语言理解能力,将网页内容解析为语义化的数据结构。同时,通过图逻辑(Graph Logic)构建灵活的爬取管线,实现了数据提取流程的可视化和模块化管理。
这种架构带来了显著优势:一方面,LLM 能够理解网页的语义内容,自动适应不同网站结构;另一方面,图结构使得数据提取流程变得透明且可调试。开发者可以像搭积木一样组合不同的处理节点,构建复杂的数据处理流水线。
主要功能特性
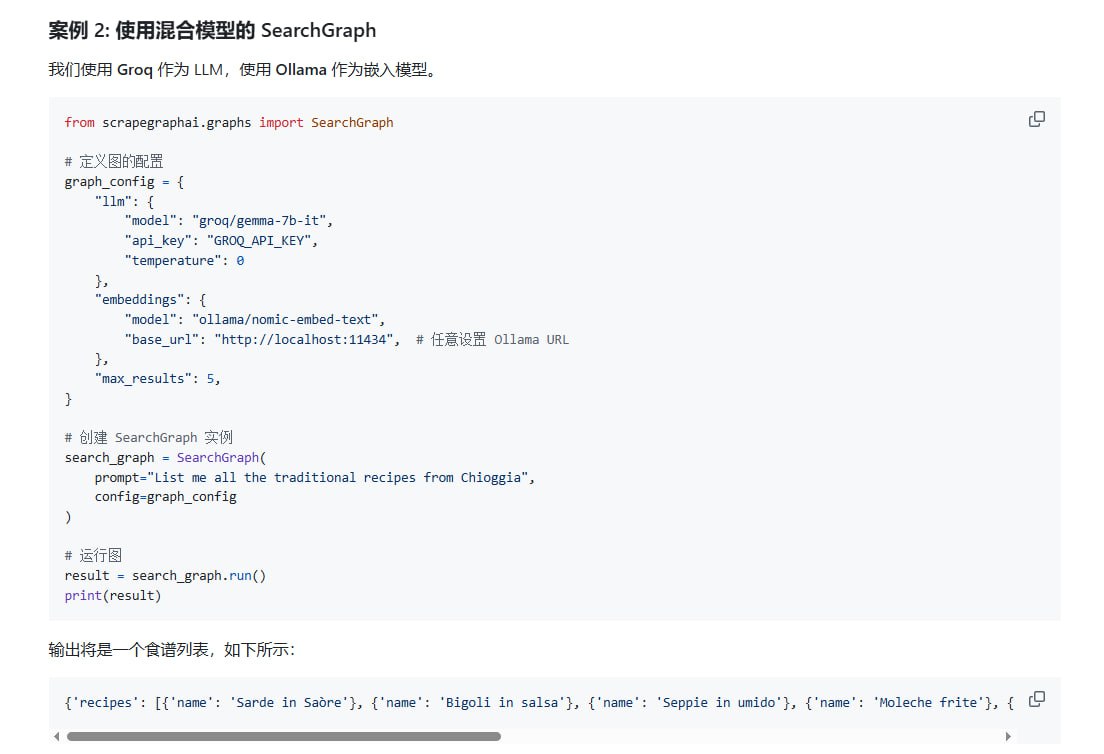
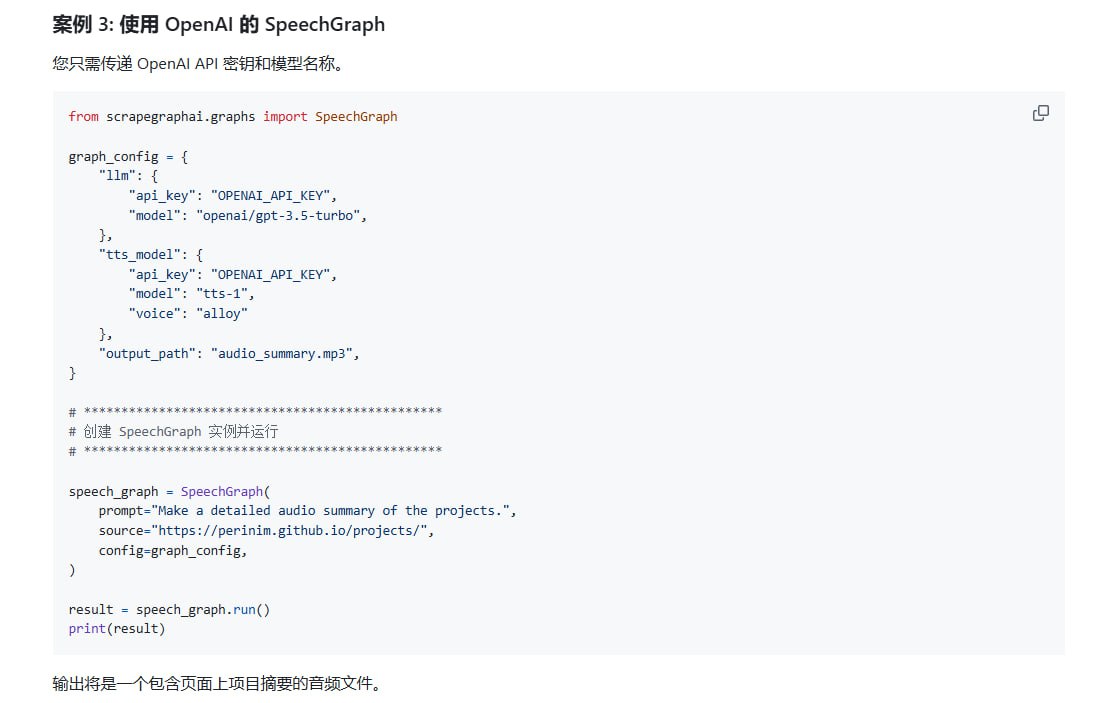
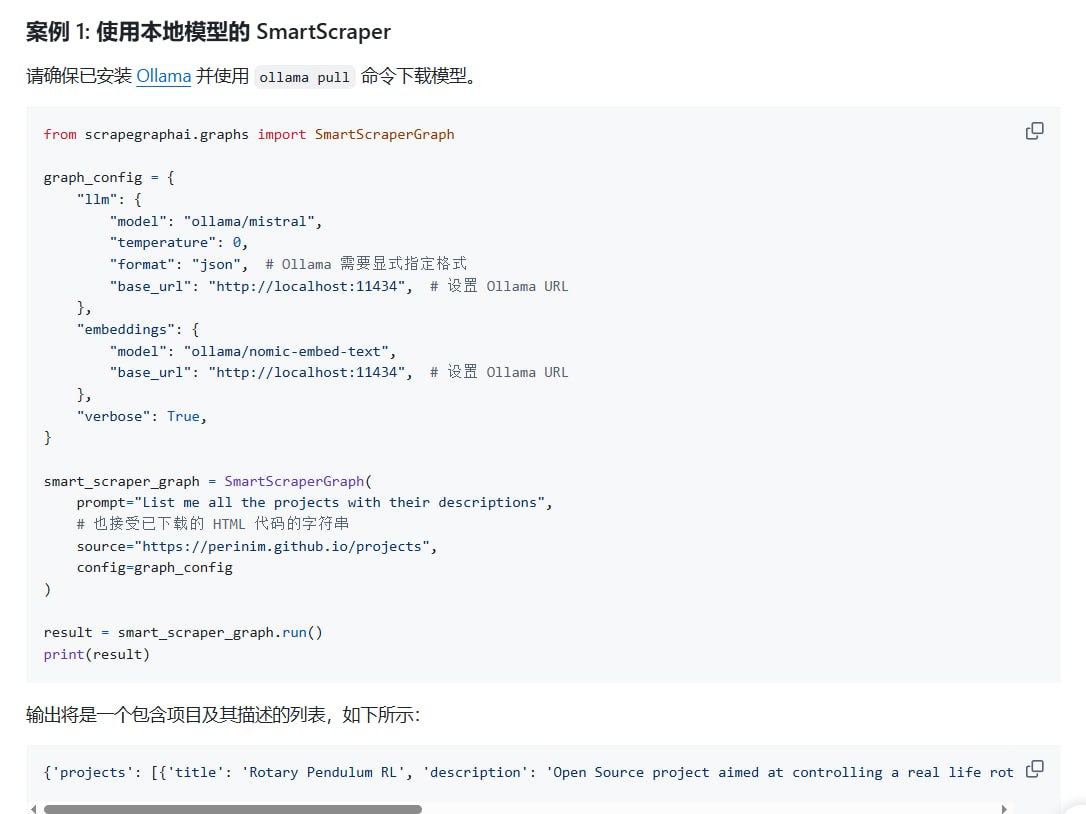
ScrapeGraphAI 提供了多种开箱即用的爬取模式,满足不同场景需求。SmartScraperGraph 专为单页智能提取设计,能够自动识别和抽取关键信息;SearchGraph 则针对多页搜索结果抓取进行了优化;SpeechGraph 可将文本内容转换为音频;而 ScriptCreatorGraph 能够自动生成 Python 爬虫脚本,大幅提升开发效率。
该框架支持广泛的输入格式,包括网页内容以及本地文档(HTML、Markdown、JSON、XML 等)。通过 Playwright 集成,能够完美处理动态加载的网页内容,解决了传统爬虫难以应对 JavaScript 渲染页面的痛点。
开发生态与集成
ScrapeGraphAI 拥有完善的集成生态,不仅提供 Python 和 Node.js SDK,还能与主流开发工具无缝衔接。它兼容 Langchain、Llama Index 等 AI 开发框架,支持 Zapier、Bubble 等低代码/无代码平台,极大地降低了二次开发门槛。
项目采用 MIT 开源协议,拥有活跃的开发者社区。截至撰写本文时,GitHub 上已获得 20.5k 星标和 1700+ Fork,显示出其受欢迎程度和技术可靠性。详尽的文档和丰富的示例代码覆盖了多语言接口,为开发者提供了坚实的学习基础。
快速入门示例
ScrapeGraphAI 以易用性著称,仅需几行代码即可完成复杂的数据提取任务。以下是一个基本使用示例:
from scrapegraphai.graphs import SmartScraperGraph
graph_config = {
"llm": {
"model": "ollama/mistral",
"temperature": 0
}
}
smart_scraper = SmartScraperGraph(
prompt="提取文章标题和作者",
source="https://example.com/article",
config=graph_config
)
result = smart_scraper.run()
print(result)
官方推荐使用虚拟环境安装,通过简单的 pip 命令即可完成部署。对于需要处理动态内容的场景,只需额外配置 Playwright 即可。
应用场景与优势
ScrapeGraphAI 特别适合以下应用场景:科研数据收集、市场竞品分析、新闻舆情监控、自动化测试数据准备等。其智能语义驱动的特性,使得它能够自动适应网站改版,显著降低了维护成本。
相比传统爬虫,ScrapeGraphAI 的最大优势在于其"一次爬取,多次利用"的理念。通过将网页内容转化为结构化数据并建立语义索引,后续可以基于自然语言查询快速提取所需信息,无需重复编写爬取逻辑。
总结与展望
ScrapeGraphAI 代表了爬虫技术的未来发展方向 - 从规则驱动转向智能语义驱动。它不仅提高了数据清洗和结构化的效率,更重要的是降低了技术门槛,使得非专业开发者也能轻松获取网络数据。
随着 LLM 技术的不断发展,我们有理由相信 ScrapeGraphAI 这类智能爬虫框架将会在数据工程领域扮演越来越重要的角色。对于需要处理网络数据的开发者和数据科学家来说,现在正是学习和采用这一创新技术的最佳时机。





