Multi-Modal Researcher:多模态研究与播客生成工具
TechFoco 精选
LangChain 发布的多模态研究工具,可根据主题和 YouTube 链接,集成视频分析与网络搜索,自动生成带引用的研究报告和对话式多角色播客。
在信息过载的时代,高效整合多源信息并生成结构化内容成为研究者的迫切需求。传统研究流程往往涉及大量手动检索、阅读和整理工作。近期,由 LangChain 团队在 GitHub 开源的 Multi-Modal Researcher 项目,旨在通过自动化流程应对这一挑战,提供从信息搜集到内容产出的端到端解决方案。

核心内容
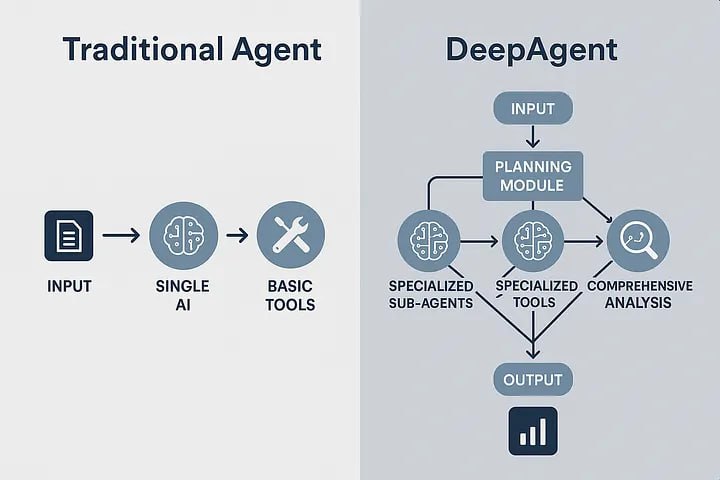
Multi-Modal Researcher 是一个一站式工具,其核心功能是根据用户输入的研究主题以及可选的 YouTube 视频链接,自动执行研究并生成成果。该工具的工作流程整合了多个关键环节。
首先,在信息搜集阶段,工具会并行执行 YouTube 视频内容分析与基于谷歌搜索的网络信息检索,以此构建一个相对丰富和立体的信息基础。
随后,在内容生成阶段,工具利用获取的信息自动撰写一份包含引用来源的研究报告。同时,它能将研究内容转化为一段自然流畅的对话式播客脚本,并支持为对话中的不同角色分配不同的语音,最终生成可播放的音频文件。
价值与影响
该工具的价值在于将分散的研究动作串联为自动化管线,显著提升了从问题提出到内容产出的效率。对于内容创作者、教育工作者或需要快速进行领域调研的专业人士而言,它能够快速生成具备一定深度的综述性材料和易于传播的音频内容。
从技术影响来看,Multi-Modal Researcher 展示了多模态 AI 在复杂工作流中的应用潜力,即如何协调文本、音频等多种信息模态的输入与输出。作为开源项目,它也为此类应用的进一步开发和定制提供了参考实现。